Chapter 6 Pharmacogenetics
The Promise of Personalized Medicine
 Take the example of a new anticancer drug, considered to be a breakthrough therapy for lung cancer. As a collection of diseases rooted in genetics, cancer has become one of the clearest examples of the potential for pharmacogenomics in predicting pharmacodynamics of a given drug in a given patient, as outlined in the following example.
Take the example of a new anticancer drug, considered to be a breakthrough therapy for lung cancer. As a collection of diseases rooted in genetics, cancer has become one of the clearest examples of the potential for pharmacogenomics in predicting pharmacodynamics of a given drug in a given patient, as outlined in the following example.
Pharmacogenetics and Pharmacogenomics


One can consider pharmacogenetics to be the original term for this field, coined in the days when tools such as microarrays did not exist and the human genome had not been mapped. In those early days it seemed unlikely or impossible that an entire genome could be analyzed in an efficient enough manner to become a useful tool in everyday medicine. Now that we have the means and the knowledge to envision a genome-wide approach to everyday prescribing, the term pharmacogenomics is often used to refer to this field. Table 6-1 lists some of the terms commonly used in pharmacogenetics.
TABLE 6-1 Definitions of Some Common Terms Used in Pharmacogenetics
| Gene | A sequence of nucleotides that corresponds to a sequence of amino acids in an entire protein or part of a protein. Genes are typically found at a specific location on a chromosome. |
| Genome | The full genetic complement of an individual. |
| Allele | Any of the alternative forms of a gene at a particular locus. These alternative forms may or may not result in different phenotypes. |
| Null allele | A mutation in a gene that leads to a loss of function. Either the gene is not expressed at all (i.e., no protein or RNA) or the product is not functional. |
| Polymorphism | Variation in DNA sequence present at a specific locus within a population. |
| Genotype | The genetic makeup of an individual. |
| Phenotype | The observable physical or biochemical characteristics of an organism. Determined by genotype and environment. |
| Monogenic | Related to or controlled by a single gene |
| Polygenic | Related to or controlled by multiple genes. A polygenic trait is a phenotype that is determined by multiple genes rather than a single gene (monogenic). |
| Germ line | Cellular lineage; genetic information that is passed from one generation to the next. |
| Haplotype | A group of alleles of different genes on a single chromosome that are so closely linked that they are inherited as a unit. |
| Somatic cell | Any cell in the body, with the exception of those involved in reproduction. |
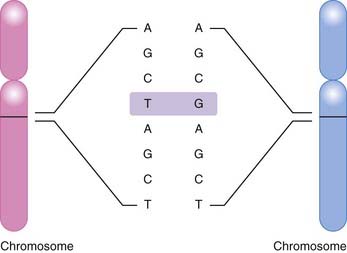
The most common basis for genetic variation, and thus the basis for a pharmacogenomic approach to drug therapy, is the single nucleotide polymorphism, or SNP (Figure 6-1). An SNP occurs when a single nucleotide is exchanged for another at a point in an individual’s genome. It is estimated that the human genome consists of approximately 3 billion nucleotides, which in specific combinations form 25,000 to 40,000 genes and encode approximately 100,000 proteins (at last count). SNPs that occur in coding regions of the genome have the potential to influence protein expression by altering an amino acid within the protein.
Pharmacokinetics
 A classic example occurred with the antituberculosis drug isoniazid (Figure 6-2). Isoniazid is acetylated (metabolized) by N-acetyltransferase 2 (NAT2), and it was observed that some patients metabolized this drug slowly (i.e., were slow metabolizers), whereas others were rapid metabolizers.
A classic example occurred with the antituberculosis drug isoniazid (Figure 6-2). Isoniazid is acetylated (metabolized) by N-acetyltransferase 2 (NAT2), and it was observed that some patients metabolized this drug slowly (i.e., were slow metabolizers), whereas others were rapid metabolizers.
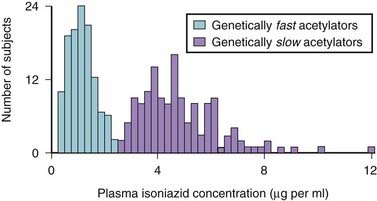
Figure 6-2 Influence of genetics on isoniazid metabolism.
(Modified from Meyer UA: Pharmacogenetics: five decades of therapeutic lessons from genetic diversity, Nat Rev Genet 2004 5:669, 2004. Reprinted by permission from Macmillan Publishers.)
Phase I Reactions, CYP450, and Genetic Polymorphisms
 Figure 6-3 demonstrates how these phenotypes can influence the dosage of a drug, in this case the antidepressant nortriptyline. Note that most patients fall into the extensive or intermediate metabolizer category.
Figure 6-3 demonstrates how these phenotypes can influence the dosage of a drug, in this case the antidepressant nortriptyline. Note that most patients fall into the extensive or intermediate metabolizer category.
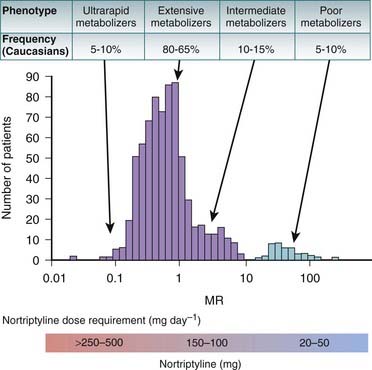
Figure 6-3 Influence of phenotype on dosing.
(Modified from Meyer UA: Pharmacogenetics: five decades of therapeutic lessons from genetic diversity, Nat Rev Genet 2004 5:669, 2004. Reprinted by permission from Macmillan Publishers.)
CYP2D6
 CYP2D6 is the CYP enzyme that is most associated with genetic polymorphisms. The frequency of polymorphisms varies greatly among ethnicities. For example, 5% to 10% of Caucasians are poor metabolizers, whereas only a small percentage (<1%) of Africans and Asians are poor metabolizers. Much of the phenotype in Caucasians is caused by the *4 null allele.
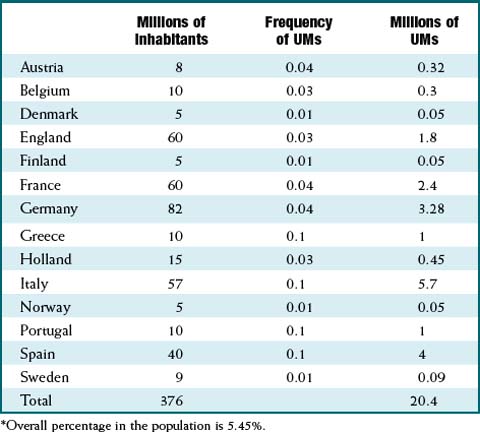
CYP2D6 is the CYP enzyme that is most associated with genetic polymorphisms. The frequency of polymorphisms varies greatly among ethnicities. For example, 5% to 10% of Caucasians are poor metabolizers, whereas only a small percentage (<1%) of Africans and Asians are poor metabolizers. Much of the phenotype in Caucasians is caused by the *4 null allele. Table 6-2 illustrates how much the frequency of CYP2D6 ultrarapid metabolizers can vary within Europe. For example, 10% of Greek citizens are ultrarapid metabolizers, whereas only 1% of people from Finland have this phenotype.
Table 6-2 illustrates how much the frequency of CYP2D6 ultrarapid metabolizers can vary within Europe. For example, 10% of Greek citizens are ultrarapid metabolizers, whereas only 1% of people from Finland have this phenotype. CYP2D6 is most commonly associated with metabolism of antidepressants, including the tricyclics (e.g., nortriptyline), selective serotonin reuptake inhibitors (SSRIs) (e.g., paroxetine), and venlafaxine. Other notable drugs using this isozyme include β-blockers (e.g., metoprolol) and antipsychotics (e.g., risperidone). Other examples include the following.
CYP2D6 is most commonly associated with metabolism of antidepressants, including the tricyclics (e.g., nortriptyline), selective serotonin reuptake inhibitors (SSRIs) (e.g., paroxetine), and venlafaxine. Other notable drugs using this isozyme include β-blockers (e.g., metoprolol) and antipsychotics (e.g., risperidone). Other examples include the following.
CYP3A4


CYP2C9
 CYP2C9 is found on chromosome 10, close to CYP2C19 as well as 2C8 and 2C18. Several alleles have been implicated in abnormal metabolism, including *2 and *3, which are much more common in Caucasians (approximately 35%) compared with African and Asian ethnicities. These alleles are associated with impaired metabolism.
CYP2C9 is found on chromosome 10, close to CYP2C19 as well as 2C8 and 2C18. Several alleles have been implicated in abnormal metabolism, including *2 and *3, which are much more common in Caucasians (approximately 35%) compared with African and Asian ethnicities. These alleles are associated with impaired metabolism.
CYP2C19
 The CYP2C19 isozyme has considerable genetic variation. The most common polymorphisms result in two null alleles, resulting in a phenotype of absent CYP2C19. This phenotype is most common in Asians (20%) and occurs in only 3% to 5% of Caucasians and Africans. The most common null alleles in Asians is *3 and in Caucasians is *2.
The CYP2C19 isozyme has considerable genetic variation. The most common polymorphisms result in two null alleles, resulting in a phenotype of absent CYP2C19. This phenotype is most common in Asians (20%) and occurs in only 3% to 5% of Caucasians and Africans. The most common null alleles in Asians is *3 and in Caucasians is *2.

CYP1A2
 There is wide variation among individuals in CYP1A2 expression and activity. These differences are also marked among different ethnicities, with lower activity found in Asians and Africans compared with Caucasians. As of 2009, 15 variants of CYP1A2 have been identified, and 158 SNPs have been found.
There is wide variation among individuals in CYP1A2 expression and activity. These differences are also marked among different ethnicities, with lower activity found in Asians and Africans compared with Caucasians. As of 2009, 15 variants of CYP1A2 have been identified, and 158 SNPs have been found.
Pharmacodynamics
 Serotonin reuptake transporters in depression. Patients with polymorphisms that lead to reduced expression of serotonin transporters may be more resistant to treatment with SSRIs. The problem with trying to draw a definitive link between this phenotype and treatment failure is the influence of other factors such as psychotherapy and even other genetic factors that may predispose the patient to treatment-resistant depression.
Serotonin reuptake transporters in depression. Patients with polymorphisms that lead to reduced expression of serotonin transporters may be more resistant to treatment with SSRIs. The problem with trying to draw a definitive link between this phenotype and treatment failure is the influence of other factors such as psychotherapy and even other genetic factors that may predispose the patient to treatment-resistant depression.
 One recent success story occurred with a drug called gefitinib, for advanced non–small cell lung cancer. The response rate, measured by a significant reduction in tumor size, was only 10% in this difficult-to-treat population. However, it was also observed that women of Asian descent with no history of smoking responded particularly well to this drug.
One recent success story occurred with a drug called gefitinib, for advanced non–small cell lung cancer. The response rate, measured by a significant reduction in tumor size, was only 10% in this difficult-to-treat population. However, it was also observed that women of Asian descent with no history of smoking responded particularly well to this drug.
The Next Step: from Genetics to Genomics
 For example, warfarin levels are influenced by alterations in CYP450 expression, as described earlier, but another key polymorphism that influences warfarin response occurs in the enzyme vitamin K epoxide reductase (VKOR), which is the pharmacodynamic target for warfarin.
For example, warfarin levels are influenced by alterations in CYP450 expression, as described earlier, but another key polymorphism that influences warfarin response occurs in the enzyme vitamin K epoxide reductase (VKOR), which is the pharmacodynamic target for warfarin.


Detection of Genetic Polymorphisms
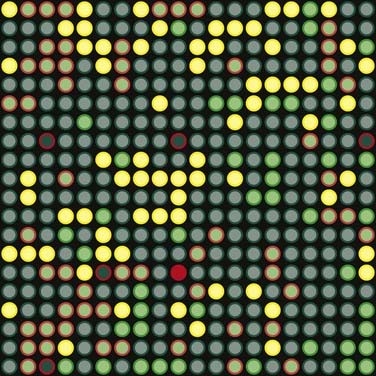
A microarray is a collection of immobilized single-stranded DNA fragments that contain a known nucleotide sequence that is used to identify and sequence DNA samples (Figure 6-4). Microarrays can be used in the analysis of gene expression. A microarray provides an automated means for identifying genes in a given sample. For example, cancerous and healthy cells may be analyzed from a single patient in order to determine the differences in gene expression between these two types of cells.






Limitations of Pharmacogenomics
 Access to therapy. The ability to target new drug development to specific genes has lead to concerns over whether patients with unusual genotypes or phenotypes will be ignored in the process. Although this is a valid concern, a counterargument is that in the past, drugs that unintentionally targeted these rare genotypes likely did not make it to market, as they were unable to prove efficacy in a wide enough population.
Access to therapy. The ability to target new drug development to specific genes has lead to concerns over whether patients with unusual genotypes or phenotypes will be ignored in the process. Although this is a valid concern, a counterargument is that in the past, drugs that unintentionally targeted these rare genotypes likely did not make it to market, as they were unable to prove efficacy in a wide enough population.


Resources for Pharmacogenetic Information
The U.S. National Institutes of Health (NIH) funds a Pharmacogenetics and Pharmacogenomics Knowledge Base, which is available at www.pharmgkb.org. The site offers pharmacogenetic data categorized by genes, pathways (e.g., renin-angiotensin-aldosterone system), SNPs, and drugs.