Chapter 9 Statistics for the Clinical Scientist
LEVEL OF MEASUREMENT AND VARIABLE STRUCTURE
Variable Structure
A dependent variable (also called outcome, endpoint, or response variable) is the primary variable of a research study. It is the behavior of such a variable that is of primary concern, including the effects (or influence) of other variables on it. An independent variable (also called explanatory, regressor, or predictor variable) is the variable whose effect on the dependent variable is being studied. Designation of which variables are dependent and which are independent in a research study establishes the variable structure. How a variable is handled statistically depends in large part on its level of measurement and its variable structure.1
EXPERIMENTAL/RESEARCH DESIGN
The three core principles of experimental design are (1) randomization, (2) replication, and (3) control or blocking. Random selection of subjects from the study population or random assignment of subjects to treatment groups is necessary to avoid bias in the results. A random sample of size n from a population is a sample whose likelihood of having been selected is the same as any other sample of size n. Such a sample is said to be representative of the population. See any standard statistics text for a discussion of how to randomize.2,3
Completely Randomized Design (CRD)
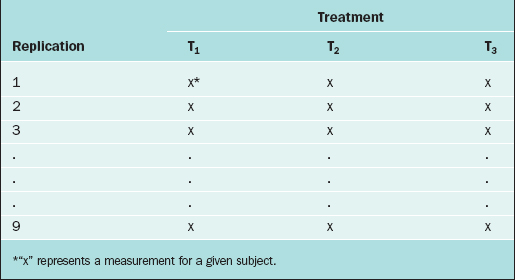
In the CRD, subjects are randomly assigned to experimental groups. As an example, suppose that the thickness of the endometrium is observed via ultrasound for women randomly assigned to three different fertility treatments (treatments T1, T2, and T3). Twenty-seven subjects are available for study, so 9 subjects are randomly selected to receive treatment T1, 9 are randomly selected from the remaining 18 to receive treatment T2, and the remaining 9 receive treatment T3. The data layout appears in Table 9-1.
Randomized Complete Block Design (RCBD)
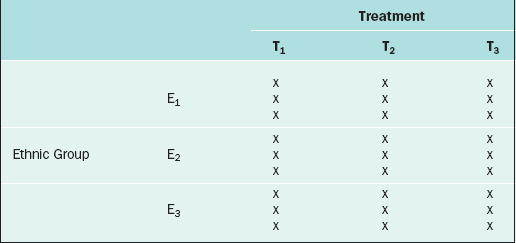
The RCBD is a generalization of the CRD whereby a second factor is included in the design so that the comparison of the levels of the treatment factor can be adjusted for its effects. For example, in the endometrial thickness study, there may be three different ethnic groups of women, E1, E2, and E3, included in the study. Because the variation of the endometrial thicknesses may be higher between two different ethnic groups than within a given ethnic group, it would be wise to block on the ethnic group factor. In this case, we would randomly select 9 subjects from ethnic group E1 and randomly assign 3 to each of the three treatments; likewise for ethnic groups E2 and E3, for a total of 27 subjects. The data layout would appear as in Table 9-2.
Repeated Measures Design
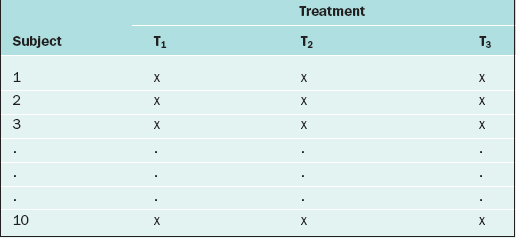
If in the RCBD the blocking factor is the subject, and the same subject is measured repeatedly, then the design becomes a repeated measures design. For instance, suppose that each of 10 subjects receives three different BP medications at different time points. For each medication, the BP is measured 5 days after the medication is started, then there is a 2-week “wash-out period” before starting the next medication. Also, the order of the medications is randomized. The data layout appears as in Table 9-3.
Many more sophisticated and complex experimental designs exist, and can be found in any standard text on experimental design.4,5 For evaluating the validity, importance, and relevance of clinical trial results, see the article by The Practice Committee of the American Society for Reproductive Medicine.6 For surveys, there are many ways in which the sampling can be carried out (e.g., simple random sampling, stratified random sampling, cluster sampling, systematic sampling, or sequential sampling).7,8
DESCRIPTIVE STATISTICAL METHODS
Continuous Variables
An important numerical measure of the centrality of a continuous variable is the mean:
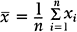
where n = number of observations and xi = ith measurement in the sample.
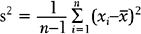
Note that the variance is approximately the average of the squared deviations (or distances) between each measurement and its mean. The more dispersed the measurements are, the larger s2 is. Because s2 is measured in the square of the units of the actual measurements, sometimes the standard deviation is used as the preferred measure of variability:
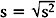
Also of interest for a continuous variable is its distribution (i.e., a representation of the frequency of each measurement or intervals of measurements). There are many forms for the graphical display of the distribution of a continuous variable, such as a stem-and-leaf plot, boxplot, or bar chart. From such a display, the central location, dispersion, and indication of “rare” measurements (low frequency) and “common” measurements (high frequency) can be identified visually.2
It is often of interest to know if two continuous variables are linearly related to one another. The Pearson correlation coefficient, r, is used to determine this. The values of r range from –1 to +1. If r is close to –1, then the two variables have a strong negative correlation (i.e., as the value of one variable goes up, the value of the other tends to go down [consider “number of years in practice after residency” and “risk of errors in surgery”]). If r is close to +1, then the two variables are positively correlated (e.g., “fetal humeral soft tissue thickness” and “gestational age”). If r is close to zero, then the two variables are not linearly related. One set of guidelines for interpreting r in medical studies is: |r| > 0.5 ⇒ “strong linear relationship,” 0.3< |r| ≤ 0.5⇒ “moderate linear relationship,” 0.1 < |r| ≤ 0.3⇒ “weak linear relationship,” and |r| ≤ 0.1⇒ “no linear relationship”.9,10
Discrete Variables
For two discrete variables the data are summarized in a contingency table. A two-way contingency table is a cross-classification of subjects according to the levels of each of the two discrete variables. An example of a contingency table is given in Table 9-4.
Table 9-4 Contingency Table for the Cross-classification of Subjects According to Treatment and Outcome.
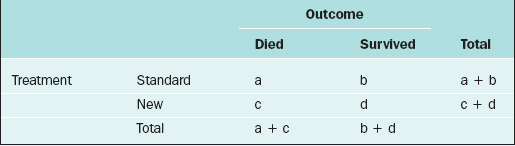
Here, there are a + b + c + d subjects in the sample; there are “a” subjects under the standard treatment who died, “b” subjects under the standard treatment who survived, and so on. If it is desired to know if two discrete variables are associated with one another, then a measure of association must be used. Which measure of association would be appropriate for a given situation depends on whether the variables are nominal or ordinal or a mixture.11,12
In medical research, two of the important measures that characterize the relationship between two discrete variables are the risk ratio and the odds ratio. The risk of an event, p, is simply the probability or likelihood that the event occurs. The odds of an event is defined as p/(1–p) and is an alternative measure of how often an event occurs. The risk ratio (sometimes called relative risk) and odds ratio are simply ratios of the risks and odds, respectively, of an event for two different conditions. In terms of the contingency table given in Table 9-4, these terms are defined as follows.
| Term | Definition |
|---|---|
| risk of death for those on the standard treatment | a/(a+b) |
| risk of death for those on the new treatment | c/(c+d) |
| odds of death for those on the standard treatment | a/b |
| odds of death for those on the new treatment | c/d |
| risk ratio of death | a(c+d)/c(a+b) |
| odds ratio of death | ad/bc |
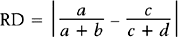
The inverse of the risk difference is the number needed to treat, NNT:
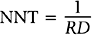
NNT is an estimate of how many subjects would need to receive the new treatment before there would be one more or less death, as compared to the standard treatment.
For example, in a study by Marcoux and colleagues13 341 women with endometriosis-associated subfertility were randomized into two groups, laparoscopic ablation and laparoscopy alone. The study outcome was “pregnancy > 20 weeks’ gestation.” Of the 172 women in the first group, 50 became pregnant; of the 169 women in the second group, 29 became pregnant (a = 50, b = 122, c = 29, and d = 140). The risk of pregnancy is 0.291 in the first group and 0.172 in the second group; the corresponding odds of pregnancy are 0.410 and 0.207. The risk ratio is 1.69 and the odds ratio is 1.98. The likelihood of pregnancy is 69% higher after ablation than after laparoscopy alone; the odds of pregnancy are about doubled after ablation compared to laparoscopy alone. The risk difference is
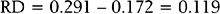
and number needed to treat is
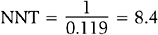
Rounding upward, approximately 9 women must undergo ablation to achieve 1 additional pregnancy.
DIAGNOSTIC TEST EVALUATION
A specialized contingency table is formed when one factor represents the results of an accurate, standard test (sometimes called the Gold Standard), and the other factor represents the results of a new, perhaps less invasive, experimental procedure. This contingency table, used for diagnostic test evaluation, is given in Table 9-5.

| Term | Definition | Interpretation |
|---|---|---|
| prevalence rate | (a+c)/(a+b+c+d) | proportion of the sample that is truly positive |
| sensitivity | a/(a+c) | proportion of true positives who test positive with the experimental procedure |
| specificity | d/(b+d) | proportion of true negatives who test negative with the experimental procedure |
| positive predictive value | a/(a+b) | proportion of those testing positive with experimental procedure who are truly positive |
| negative predictive value | d/(c+d) | proportion of those testing negative with experimental procedure who are truly negative |
| false positives | b | number of subjects who are negative but test positive |
| false negatives | c | number of subjects who are positive but test negative |
Use of these measures provides insight into the effectiveness of a new, experimental procedure relative to the Gold Standard.14–16 To select that cutoff point for the experimental procedure that defines a “+” or “–” result in such a way that sensitivity and specificity are optimized, Receiver Operating Characteristic (ROC) curves are used.17 The ROC curve is a plot of the sensitivity of test (Y-axis) versus the false positive rate (X-axis; 1-specificity). This measure is used to assess how well a test can identify patients with a disease. An area under the curve of 1 is a perfect test and 0.5 is a useless test.
ESTIMATION
Confidence Intervals
Although the point estimate is expected to be “close” to the parameter value, we are often interested in how close it is. Therefore, many researchers prefer to use a confidence interval to estimate the parameter. A confidence interval is an interval for which the endpoints are determined by statistics calculated from the sample; for this interval there is a high probability (usually set at 95%) that it contains the population parameter value. For most applications, the point estimate is at the midpoint of the confidence interval. In the example above, if the 95% confidence interval for the mean fetal HSTT is [7.2, 12.2], then we say that we are 95% confident that the true mean fetal HSTT falls between 7.2 mm and 12.2 mm. This interval can also be written as 9.7 mm ± 2.5 mm. The value 2.5 is called the margin of error; it represents the range of values on either side of the point estimate, 9.7 mm, that are regarded as “plausible” values of the true mean fetal HSTT. Values farther than 2.5 mm away from the point estimate are regarded as “implausible” values. In this way, the confidence interval, with its margin of error, provides a measure of the reliability of the point estimate.
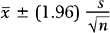
This particular formula is valid for relatively large samples, say n ≥30. Note that the margin of error is
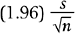
which decreases when n increases.
The basic formula for most confidence intervals is
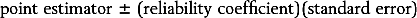
where the reliability coefficient is a percentile taken from an appropriate distribution, and the standard error is the standard deviation of the estimator. In the confidence interval for a population mean given above, the point estimator is the sample mean,
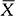
the reliability coefficient is the 97.5th percentile from the standard normal distribution, and the standard error is
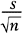
Refer to any standard statistics text to obtain confidence interval formulas for population parameters (e.g., McClave and Sincich2).
TESTS OF HYPOTHESES

where μ = mean fetal HSTT.
Type I and II Errors, Statistical Power
Statistical power is defined as 1 – β, which is the probability of correctly rejecting H0 (i.e., rejecting H0 when H0 is really false). In practice, we would like the statistical power to be high (at least 0.8) for those alternatives (i.e., values of the parameter in HA) that are deemed to be clinically important. As indicated above, β decreases as n increases, and hence power increases with n.
STATISTICAL PROCEDURES
Comparison of Means
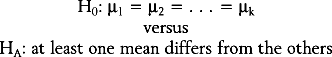
For example, one may be interested in comparing the mean fetal HSTT among four ethnic groups of women: white, African-American, Asian, and “other.” If H0 is rejected (e.g., P < 0.05), then it is concluded that the mean fetal HSTT is not the same for all four ethnic groups. The determination of how the four means differ from one another is made through a multiple comparisons procedure. There are many such procedures, but the recommended ones are Tukey’s HSD (“honestly significant difference”) post hoc test, the Bonferroni-Dunn post hoc test, or the Neuman-Keuls test.18 In the special case of the ANOVA in which k = 2, so that the means of two populations are compared based on two independent samples, the statistical test is called the two-sample (or pooled-sample) t-test.
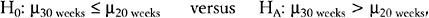
where μ represents the mean fetal HSTT.
What is an appropriate sample size to use for a two-sample t-test or a paired t-test? If the two populations have comparable standard deviations, then a sample of size at least n = (16)(sc/δ)2 for each group will ensure 80% power for the two-sample t-test conducted at the 0.05 level of significance, where sc is the estimate of the common standard deviation of the two samples, and δ is a mean difference that is deemed to be clinically important.19 For a paired-sample t-test, a sample of size at least n = (8)(sd/δ)2 pairs will ensure 80% power for a 0.05 level test, where sd is the standard deviation of the differences of the paired measurements.19
STUDYING RELATIONSHIPS/PREDICTION
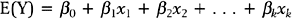
A major result of the multiple regression analysis is the estimation of the regression coefficients βi = 1, 2, …, k, and the statistical test of significance for each coefficient. The hypotheses being tested are:
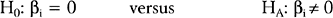
for i = 1, 2, …, k.
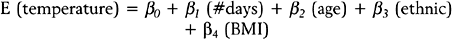
There are two cautionary notes concerning the predictor variables in any regression model, including logistic and Cox regression models:
What is an appropriate sample size for a multiple regression? In general, a sample size of at least n = 10k should be used,22 where k is the number of predictors in the model. However, this guarantees nothing about the statistical power. To ensure 80% power of detecting a “medium” size effect, the sample size should be at least n = 50 + 8k.24
COMPARING PROPORTIONS
Consider the comparison of two population proportions,
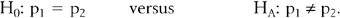
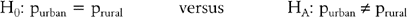
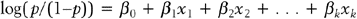
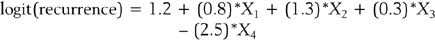
What is an appropriate sample size for a logistic regression? Consider a binary outcome variable. In general, the number of subjects falling into the smaller of the two outcome levels should be at least 10k, where k = number of predictor variables in the logistic regression equation.25–27 To ensure a specified power, a sample size software or a table28 must be used.
COMPARING SURVIVAL RATES
Two important quantities for evaluating survival data are (1) the survival function and (2) the hazard function. The survival function, S(t), is the probability that a subject experiences the event of interest after time t; S(t) = P[X>t], where X represents the time until the event of interest occurs. The estimated values of S(t) plotted against t are called Kaplan-Meier curves.29
The hazard function is, mathematically,
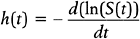
The standard statistical model for analyzing survival data is the Cox proportional hazards regression model.30 In this model the hazard rate is regressed on a set of regressor variables,
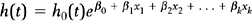
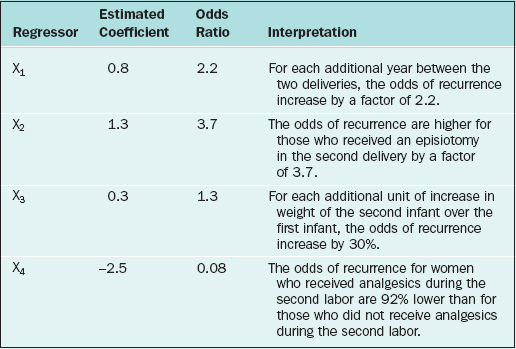
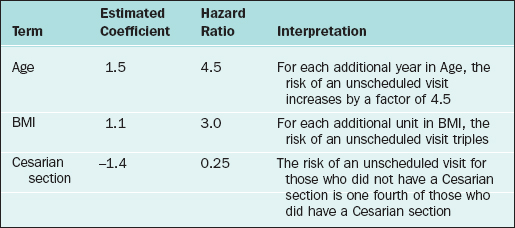
where h0(t) is an arbitrary baseline hazard rate. This model is used to study the effects of the regressor variables on the hazard function. Suppose that 1000 new mothers are monitored from delivery to the baby’s first unscheduled hospital visit. The study period lasts 2 years, and new deliveries are enrolled during the first year. The hazard function (for baby’s first unscheduled hospital visit) is regressed on mother’s age, mother’s BMI, and whether the mother delivered by cesarean section (coding: 1=Yes, 2=No). In the table below, the results are presented along with the interpretation. Assume that all of the β-coefficients are statistically significant.
What is the appropriate sample size for a Cox regression? In general, the number of events (i.e., uncensored observations) in the sample should be at least 10k, where k = number of predictors in the Cox regression model.31 Van Belle27 recommends that the sample size should be n = 16/(ln(h))2 per group, where h is a hazard ratio that is deemed to be clinically important.
CONCLUSION
1 Khamis HJ. Deciding on the correct statistical technique. J Diagn Med Sonogr. 1992;8:193-198.
2 McClave JT, Sincich T. Statistics, 8th ed. Upper Saddle River, N.J.: Prentice-Hall, 2000.
3 Zar JH. Biostatistical Analysis, 3rd ed. Upper Saddle River, N.J.: Prentice-Hall, 1996.
4 Hicks CR. Fundamental Concepts in the Design of Experiments, 4th ed. New York: Saunders College Publishing, 1993.
5 Montgomery DC. Design and Analysis of Experiments, 5th ed. New York: John Wiley & Sons, 2001.
6 The Practice Committee of the American Society for Reproductive Medicine. Interpretation of clinical trial results. Fertil Steril. 2004;81:1174-1180.
7 Thompson S. Sampling, 2nd ed. New York: John Wiley & Sons, 2002.
8 Tryfos P. Sampling Methods for Applied Research. New York: John Wiley & Sons, 1996.
9 Burns N, Grove SK. The Practice of Nursing Research, 4th ed. Philadelphia: W.B. Saunders, 2001.
10 Cohen J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed. Mahwah, N.J.: Lawrence Erlbaum Associates, 1988.
11 Goodman LA, Kruskal WH. Measures of Association for Cross Classifications. New York: Springer-Verlag, 1979.
12 Khamis HJ. Measures of association. In Armitage P, Colton T, editors: Encyclopedia of Biostatistics, 2nd ed., New York: John Wiley & Sons, 2004.
13 Marcoux S, Maheux R, Berube S. Laparoscopic surgery in infertile women with minimal or mild endometriosis, Canadian Collaborative Group on Endometriosis. NEJM. 1997;337:217-222.
14 Khamis HJ. Statistics refresher: Tests of hypothesis and diagnostic test evaluation. J Diagn Med Sonogr. 1987;3:123-129.
15 Khamis HJ. An application of Bayes’ rule to diagnostic test evaluation. J Diagn Med Sonogr. 1990;6:212-218.
16 Riegelman RK. Studying a Study and Testing a Test: How to Read the Medical Literature. Boston: Little, Brown and Company, 1981.
17 Metz CE. Basic principles of ROC analysis. Semin Nuclear Med. 1978;8:283-298.
18 Hsu JC. Multiple Comparisons, Theory and Methods. New York: Chapman & Hall, 1996.
19 Lehr R. Sixteen s-squared over d-squared: A relation for crude sample size estimates. Statistics Med. 1992;11:1099-1102.
20 Draper NR, Smith H. Applied Regression Analysis, 2nd ed. New York: John Wiley & Sons, 1981.
21 Myers RH. Classical and Modern Regression with Applications, 2nd ed. Boston: PWS-Kent, 1990.
22 Kutner MH, Nachtsheim CJ, Neter J, Li W. Applied Linear Statistical Models, 5th ed. Boston: McGraw-Hill, 2005.
23 Tabachnik BG, Fidell LS. Using Multivariate Statistics, 4th ed. Boston: Allyn and Bacon, 2001.
24 Green SB. How many subjects does it take to do a regression analysis? Multivar Behav Res. 1991;26:499-510.
25 Harrell FE, Lee KL, Matchar DB, Reichert TA. Regression models for prognostic prediction: Advantages, problems, and suggested solutions. Cancer Treat Rep. 1985;69:1071-1077.
26 Peduzzi PN, Concato J, Kemper E, et al. A simulation study of the number of events per variable in logistic regression analysis. J Clin Epidemiol. 1996;99:1373-1379.
27 van Belle G. Statistical Rules of Thumb. New York: John Wiley & Sons, 2002.
28 Hsieh FY. Sample size tables for logistic regression. Statistics Med. 1989;8:795-802.
29 Kaplan EL, Meier P. Nonparametric estimation from incomplete observations. J Am Statistic Assoc. 1958;53:457-481.
30 Cox DR. Regression models and life tables (with discussion). J Roy Statist Soc B. 1972;34:187-220.
31 Harrell FE, Lee KL, Califf RM, et al. Regression modeling strategies for improved prognostic prediction. Statist Med. 1984;3:143-152.
32 Khamis HJ. Statistics refresher II: Choice of sample size. J Diagn Med Sonogr. 1988;4:176-184.
33 Khamis HJ. Statistics and the issue of animal numbers in research. Contemp Topics Lab Animal Sci. 1997;36:54-59.
34 Khamis HJ. Assumptions in statistical analyses of sonography research data. J Diagn Med Sonogr. 1997;13:277-281.
35 Gibbons JD. Nonparametric Statistical Inference, 2nd ed. New York: Marcel Dekker, 1985.
36 Sheskin DJ. Parametric and Nonparametric Statistical Procedures, 3rd ed. New York: Chapman & Hall, 2004.