Chapter 29 Data Management
Building a Successful Outcomes Information System
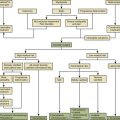
The database itself is but one component of an efficient scheme for data collection, storage, and retrieval. At this point it is necessary to highlight a crucial aspect of understanding outcomes information systems (outcomes systems). The word system is used here to accent the simple distinction between the data “store,” or database (i.e., the electronic data storage mechanism), and its functional environment. Although each system typically has a database at its core that is responsible for data storage, the overall system is much broader, including database management software, data processing software, presentation applications (i.e., browsers), user interfaces (i.e., input and output screens), and the hardware on which it operates (Fig. 29-1). The term database simply refers to the data storage mechanism. Within the context of an overall information system, the database can perform properly, but the database is entirely useless outside of the system. Ideally, a well-designed database drives the development of its interrelated technical components (i.e., hardware and software), resulting in an efficient and elegant solution for outcomes research.
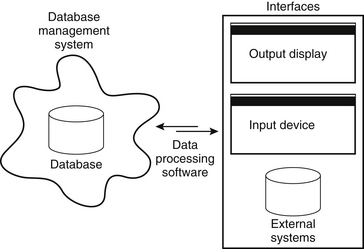
This discussion is intended to help bridge the divide between individuals who desire a medical outcomes information system and those who possess the knowledge and skills to build and maintain it. There is often a significant gap between the perceived resource requirements, in terms of time, technology, and human resources, the creation of such a system, and the actual requirements. This is especially true with respect to the time necessary for design and development. However, effective communication between the users and the technical staff (i.e., the individuals commissioned to build and maintain a system) can drastically shorten the development cycle. Therefore, here this relationship is analyzed throughout all of the system development stages, beginning with the initial conceptual development and finishing with implementation. The system development process is deconstructed into three key stages: definition, design, and deployment.
System (Project) Definition
Determining Data Elements
Beyond the selection process, all of the data elements must be presented in a standardized and concise manner that can be readily adopted by all of the system participants (patients and health care providers). For provider-entered data elements, standardizing the terms used to describe spinal disorders and their manifestations is necessary to allow accurate categorization of patients within each specific disorder. This standardization process is essentially the process of establishing the common language that is subsequently used by all participants. Health care providers will use it to describe their patients, patient symptoms, pathologies, treatment options, and the course of therapy. For patient-reported data, using validated scales and questions that are at the appropriate education level is good practice and optimizes the accuracy of the information.
System Design
Data Mapping and Modeling
On a grander scale, the system analyst must also consider established protocols for patient care to design a system that can be incorporated into the clinical workflow with the least amount of resistance. This includes assessing the physical layout of clinical areas, clinical and support staff availability for outcomes system functions, and patient flow throughout the clinical areas, and so on. If workstations are available in a waiting area, perhaps a patient can complete an electronic survey while he or she is waiting to see a physician. Otherwise, paper surveys can be used, but it must be determined whether the surveys, once collected, will then be scanned into the data store or whether data entry will be the responsibility of a staff person.
Relational Database
Each row groups attributes of a specific entity. In a table that stores patient information, every row stores attributes of a specific patient. This contrasts the columnar view, which provides a longitudinal perspective of one specific attribute across the entire population (i.e., all of the ages of patients are stored in the same column). Consequently, the intersection of a row and column is a special occurrence within each table. The intersection represents a specific characteristic of the entity being defined by the row. For example, the patient table in Figure 29-2 contains the columns “PatientKey,” “LastName,” “FirstName,” “Birthdate,” “Physician,” “AppointmentDate,” and “Diagnosis.” The intersection of the first row and the column called “FirstName” indicates that the entity being described (in this case, a patient) has the first name “Jane.”
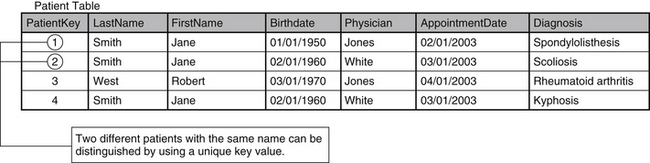
The reliability of these intersections is inextricably bound to the ability to distinguish each row from every1 other row. This requires the assignment of a unique identifier, or primary key, to every row within the table. A common instinct for the row identification in a table that houses patient information is to use the patient’s name as the primary key. This solution, however, breaks down as soon as two different patients with the same name are entered. The medical record number is usually a better alternative, providing a completely unique value for identifying each patient. However, for reasons discussed previously (patient privacy law), the medical record number is not generally a viable option. A more appropriate method is to assign an independent, arbitrary value as a primary key for the row. One column within the table is dedicated to the primary keys (see Fig. 29-2), and will be structured to require that each value is unique.
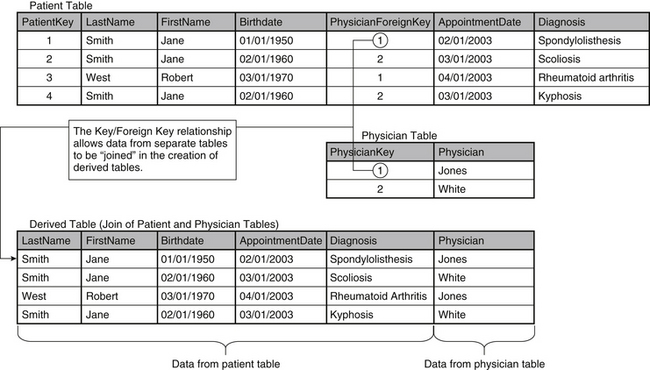
By assigning a distinct value as primary key for each row, two different patients with the same name can now be identified unambiguously. The uniqueness of the primary key is important because it serves as a device to connect different tables within the database. Establishment of these connections, or relationships, across tables becomes essential as the database is normalized (a process of “tuning” the data storage system, discussed later in this chapter). If each row cannot be identified and referenced individually, relationships between separate tables become confused and unreliable. In the relational model, a table’s primary key provides a means for other tables to reference its information. When the primary key of one table is stored in another as a link between them, it is called a foreign key, and it establishes the relationship between the two tables. As a result, data elements that are stored in separate tables in a database can be combined to form new tables (called derived tables), as Figure 29-3 demonstrates. By linking records from the patient and physician tables through the “PhysicianForeignKey” column, a derived table is created that contains the relevant data from both tables.
Normalization
The rules of normalization, originally defined by Dr. E F. Codd, deal primarily with the elimination of data redundancies that lead directly to flawed data and impractical, inefficient data management in relational systems.2 The rules of normalization provide solid guidelines for building effective relational database systems. Normalization leverages the actual structure of the database to improve the integrity of the data. In practice, normalization is manifested as a “spreading” of the data, as information is stored throughout the database in many separate tables that are interrelated. Entities should be grouped and related in the same manner that they would be observed in their real-world roles. In the same way, the differences should be maintained by using separate tables (i.e., a patient table should not contain information concerning the physician). Although this idea is fairly simple, it is the foundation of normalizing the database.
First Rule of Normalization
The first rule of normalization is somewhat academic: each column in a given row contains one—and only one—value. Violation of this principle is relatively easy to recognize and correct. It would seem unnatural, for instance, to include a column with the head “Physician/Diagnosis” that contains both the name of the physician and the patient’s diagnosis. This problem is easily resolved by separating the two independent values into two distinct columns, “Physician” and “Diagnosis.” A subtler example is demonstrated in the storage of a patient’s name in a single column, rather than creating one column for the first name and another for the last name. Arguments can be made that this is not truly a violation of first normal form, but the two-attribute approach is more suitable because of the common use of last name as an identifier and sort item for groups of patients.
The higher-order rules of normalization deal more specifically with the reduction of data in the relational system. The storage of duplicate information in multiple locations causes the process of modification to become unruly. For example, in the database depicted in Figure 29-2, if Dr. Jones gets married, triggering a name change, two rows are affected (those with values of 1 and 3 in the “PatientKey” column). As a result, the physician values stored in the “Physician” column of each record must be updated, signaling a data storage redundancy. In Figure 29-3, this redundancy is corrected by isolating the physician information into its own table (“Physician”). The data have been effectively reduced, so that the same change requires the update of only one row. This type of data reduction demonstrates the importance of the primary key in the relational model. Separate, related tables are “bridged” by storing the primary key from one table (i.e., “PatientKey”) as a foreign key in another (i.e., “PatientForeignKey”).
Second Rule of Normalization
Although this design strengthens the overall structure of the database, Figure 29-3 has yet to satisfy the standard set by the second rule of normalization: every nonkey attribute must be irreducibly dependent on the primary key.3 The second rule deals with the logical grouping of data elements. Tables should be designed to mirror their real-world counterparts. A table commissioned to store patient data should contain attributes of the patient only, completely separate from other entities, such as diagnosis or physician.
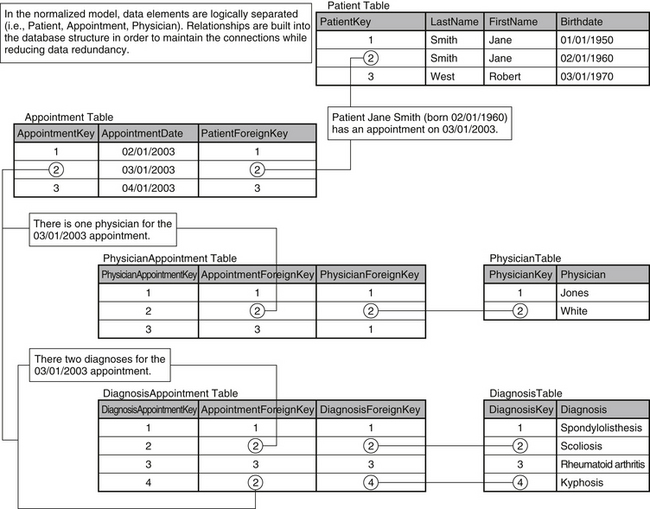
To achieve second normal form, the tables must be restructured. Duplication can be easily identified while reviewing the content of the database, as shown in Figure 29-3. The patient named Jane Smith, who was born February 20, 1960, has two rows in the “Patient” table. As a result, her name and date of birth are repeated unnecessarily. This repetition is caused by the inclusion of the attribute “Diagnosis” as part of the “Patient” table, even though it is functionally independent. To rectify this situation, the “Patient” table must be separated again into a set of smaller tables. This process, known as decomposition, must be “lossless” to maintain the integrity of the data. Just as the term implies, lossless decomposition is a process that retains all essential data and removes redundant values while preserving the ability to reproduce the content of the original table, as needed. This process is demonstrated in Figure 29-3, in which the “Patient” and “Physician” tables are stored separately but can be joined to form a derived table that contains the data from both. It should be noted that derived tables are temporary and should not be included in the long-term data storage design. Derived tables simply provide a convenient, short-term view of related data from separate tables.
In the current example (see Fig. 29-3), the “Diagnosis” column is the source of the redundancy and must be sequestered to its own table. However, this separation must be done without any data loss. To accomplish this, an “Appointment” table should be added to serve as a bridge between each patient and his or her associated diagnoses. The “Appointment” table also connects patients and physicians.
The relationship between patients and appointments is established by storing the “PatientKey” for each patient in the “PatientForeignKey” column. The relationship between the “Patient” and “Appointment” tables in the database mirrors the relationship between patients and appointments in reality. The relationship can be best described as “one-to-many,” in which one patient can have many appointments. If this relationship is built into the database design, a patient can have multiple appointments (requiring multiple entries in the “Appointment” table) but only one entry is required in the “Patient” table. As a result, the data redundancy visible in Figure 29-3 (in columns “LastName,” “FirstName,” and “Birthdate”) is eliminated.
The process of decomposition continues as the diagnosis and physician information are also separated. The relationships between the patient and the associated physician and diagnoses must be maintained. The “Appointment” table is used to connect the “Patient,” “Physician,” and “Diagnosis” tables. Once again, the database design draws from a real-world example. An appointment is the point in the treatment process at which the patient meets with the physician and the physician determines the diagnosis. The database model is a natural extension of this relationship. The restructured database is shown in Figure 29-4.
Technologic Vulnerabilities
The most important factor when considering system vulnerabilities is the protection of data. Access to the database should be restricted to legitimate users, and the nature of access should be structured to fit the use patterns of each specific user. Full access to every component of the database should be limited to the database administrator. Read-only access for all other users is preferred, reserving write access (update) for situations that require it. For example, a physician will need to update the tables used for any direct data entry (i.e., symptoms, diagnosis), implying write access. However, the same physician will not need permission to update a patient survey table, in which read-only access will suffice. Provision of full access to the database for all users can easily result in the corruption of data.
Participation provides another interesting challenge in the pursuit of an outcomes system. Data collection systems that are too costly in terms of time, effort, or resources will not succeed. A successful model is one that leaves the smallest possible footprint, a prospect that is best realized through collaboration. In the health care industry, the availability of information has increased exponentially in recent years. Pursuant to this, outcomes systems are afforded the opportunity to draw from many sources within the organization. Data are collected and retained for every patient throughout the scheduling, registration, treatment, and billing processes as the trend of paperless patient care continues. Consequently, information is typically stored in many different systems throughout the organization, and effective outcomes systems draw from these disparate data sources whenever possible. Not only does the sharing of data reduce the possibility of errors stemming from data entry, but it also minimizes the level of effort necessary from the participants (both patients and physicians). For example, if a patient’s demographic information is gathered for the registration process, it should not be necessary to collect it again when the patient completes a survey. As multiple systems are leveraged within the outcomes system, the resulting automation can significantly reduce the risk of unverified data. Moreover, participation levels improve as the required effort decreases.
Deployment
Successful deployment of the system is predicated on clear communication about the implementation schedule, tasks, and implications for all involved. This includes communication among the team members, and perhaps most importantly, between the team and all affected parties. Advanced notification and discussion of timeframes, expectations, and the roles of all operational and clinical personnel in assisting patients and physicians in data collection are needed. The establishment of feedback loops for communicating implementation problems and issues is essential to the deployment process. People need to know, on a real-time basis, how to report technical malfunctions or process issues. In turn, responsive troubleshooting by members of the project team is equally essential. It is suggested that the project leader or his or her designee give timely project updates and process statistics to key stakeholders, including clinical departments, medical staff, and management, to keep people informed of the implementation schedule and milestones.
Measuring Success
Objective Metrics
• The number/percentage of all patients seen, in the target population, from whom patient-reported data are collected. Example: 89 of 100 (89%) patients seen in March 2002 completed the required data collection survey.
• The number/percentage of all patients seen, in the target population, for whom physician-reported data were collected. Example: Physicians submitted data on 90 of 100 (90%) patients seen in March 2002.
• The number/percentage of survey “matches” between physician and patient-collected data. Example: For the 200 surveys collected from patients during March 2002, 190 (95%) surveys were collected on the same patients by physicians.
• The number/percentage of surveys (either physician or patient) completed entirely (no questions or sections left blank or illegibly marked). Example: 95 of 100 (95%) surveys completed by physicians (or patients) were complete.
• The average and range of time required for patients to complete a survey. Example: Patients spent between 10 and 35 minutes to complete a survey (average, 15 minutes).
• The average and range of time required for physicians to complete a survey. Example: Physicians spent between 5 and 15 minutes to complete a survey (average, 7 minutes).
• Based on a random cross-check of selected fields from 20 completed physician-reported surveys with the corresponding patient medical record, the number and percentage of surveys in which the survey data were in agreement with the medical record. Example: In 16 of 20 (80%) physician surveys, the selected data fields were in complete agreement with the medical record.
• Quantification of individual physician participation relative to other physicians within the department (e.g., physician A provided data on 62% of patients compared with a department-wide percentage of 84%).
Subjective Metrics
• Patient-reported perceptions of the time required and user-friendliness of the surveys
• Perceptions of the operational and clinical personnel with respect to the ease of administration of the patient surveys, user-friendliness, and so on
• Patient expectations about treatment
• Patient satisfaction with the clinical encounter and health care providers
• Measures of pain and functional limitation
• Usefulness and appropriateness of output reports that are produced and provided to the clinicians, as well as the clinicians’ impressions about the data
• Clinicians’ impressions and those of the entire project team, as to the cost-benefit ratio of system inputs versus outputs
Codd E.F. A relational model of data for large shared data banks. Communications of the ACM. (Association for Computing Machinery). 1970;13(6):377-387.
Date C.J. Introduction to database systems. Reading, MA: Addison Wesley Longman; 2000.
Frymoyer J.W., Cats-Baril W.L. An overview of the incidences and costs of low-back pain. Orthop Clin North Am. 1991;22:263-271.
1. Frymoyer J.W., Cats-Baril W.L. An overview of the incidences and costs of low-back pain. Orthop Clin North Am. 1991;22:263-271.
2. Codd E.F. A relational model of data for large shared data banks. Communications of the ACM. (Association for Computing Machinery). 1970;13(6):377-387.
3. Date C.J. Introduction to database systems. Reading, MA: Addison Wesley Longman; 2000.