6. Systematic reviews and meta-analyses in CAM
contribution and challenges
Klaus Linde and Ian D. Coulter
Chapter contents
Introduction119
The protocol120
The question120
Searching the literature121
Selecting the relevant studies122
Extracting information123
Assessing quality123
Summarizing the results124
Checking the robustness of results127
Who should do systematic reviews?127
How to identify existing systematic reviews129
Limitations of systematic reviews129
How should we use systematic reviews in CAM?131
Introduction
Every year more than two million articles are published in over 20 000 biomedical journals (Mulrow 1995). Even in speciality areas it is impossible to keep up to date with all relevant new information. In this situation systematic reviews hold a key position to summarize the state of the current knowledge. A review is called systematic if it uses predefined and explicit methods for identifying, selecting and assessing the information (typically research studies) deemed relevant to answer the particular question posed. A systematic review is called a meta-analysis if it includes an integrative statistical analysis (pooling) of the included studies.
Within complementary medicine systematic reviews are of major relevance. This chapter aims to give an introduction on how to read and how to do a systematic review or a meta-analysis, and discusses advances and limitations of this method.
Most available systematic reviews on complementary medicine have focused on treatment effects. Therefore, most of the content of this chapter refers to such reviews. But of course, it is possible to do systematic reviews on other topics, for example the validity and reliability of diagnostic methods (for example, on iridology: Ernst 1999), side-effects (for example, on side-effects and interactions of St John’s wort: Knüppel & Linde 2004), on surveys (for example, on reasons for and characteristics associated with complementary and alternative medicine (CAM) use among adult cancer patients: Verhoef et al. 2005), observational studies of association of risk or protective factors with major diseases (for example, whether the consumption of green tea is associated with a lower risk of breast cancer: Seely et al. 2005), or even on other systematic reviews (for example, a review of reviews of acupuncture: Linde et al. 2001a). The principles are the same as for reviews of studies on treatment effects but details in the methodological steps can differ.
The protocol
A systematic review is, in principle, a retrospective study. The unit of investigation is the original research study (primary study), for example, a randomized controlled trial (RCT). The retrospective nature limits the conclusiveness of systematic reviews. Nevertheless, the methods of retrospective studies should be defined as far as possible in advance.
The protocol of a systematic review should have subheadings similar to those in this article. For writing a feasible and useful protocol it is necessary to have at least some basic ideas what and how much primary research is available. Therefore, in practice the protocol of a systematic review often has to be developed in a stepwise approach where the methods are defined rather loosely in the early screening phase and then become increasingly specific.
Examples of detailed protocols of systematic reviews can be found in the Cochrane Library (www.cochrane.org), the electronic publication of a worldwide network for systematic reviews of health care interventions.
The question
As in any research a clear and straightforward question is a precondition for a conclusive answer. A clearly defined question for a systematic review on a treatment is, for example, whether extracts of St John’s wort (Hypericum perforatum) are more effective than placebo in reducing the clinical symptoms of patients with major depression (Linde et al. 2008). A question of this type already predefines the group of patients (those with major depression), the type of experimental (extracts of St John’s wort) and control intervention (placebo) as well as the outcome of interest (clinical symptoms of depression). Systematic reviews on such narrowly defined questions make sense, particularly when a number of similar studies are available but their results are either not widely known or contradictory, or if the number of patients in the primary studies is too small to detect relevant differences with sufficient likelihood.
In complementary medicine the number of studies on a particular topic is often small. If the question is very narrow it may be that only a few or even no relevant trials can be identified. For example, a systematic review has been performed to assess whether there is evidence from randomized trials that acupuncture is effective for treating swallowing difficulties in patients with stroke (Xie et al. 2008). Only one trial met the inclusion criteria. While it can be easily concluded from such a review that there is very little evidence, this is not very satisfying for reviewers or readers.
Sometimes it may be useful to ask broader questions, for example: ‘Is there evidence that acupuncture can reduce symptoms associated with acute stroke?’ Such a review will give a more descriptive overview of inhomogeneous studies (regarding study design, outcomes, prevention or treatment). It will be more hypothesis-generating than hypothesis-testing.
Searching the literature
An obvious precondition for a good systematic review is that the relevant literature is covered comprehensively. Until the late 1990s the majority of studies in the area of complementary medicine were published in journals that were not covered by the most important electronic databases such as PubMed/Medline or Embase. This has changed over the last 15 years. Several journals focusing on research in CAM are now included in these databases, and many studies are published in ‘conventional’ medical journals. Studies published in journals not listed in these major databases tend to have lower quality (Linde et al. 2001b). However, literature searches restricted to the major databases might miss relevant high-quality studies. Therefore, depending on the subject it will be necessary that reviewers should search more specialized databases, and in any case they should use additional search methods.
A very effective and simple method is checking the references of identified studies and reviews relevant to the topic. This method often also identifies studies which are published only as abstracts, in conference proceedings or books. The problem of this method can be that studies with ‘undesired’ results are systematically undercited. Contacting persons, institutions or industry relevant to the field can help both in identifying new sources to search (for example, a specialized database which was unknown to you before) and obtaining articles directly. Finally, handsearching of journals and conference proceedings is a possibility, although this often surpasses the time resources of reviewers.
A problem that has to be kept in mind is that specific complementary therapies and research activities might be concentrated in certain countries. For example, thousands of randomized trials on traditional Chinese medicine have been performed in China. These articles have been published almost exclusively in Chinese journals and in Chinese language. While western researchers are often reluctant to search and include studies from China due to their generally low quality (Wang et al. 2007), the almost exclusively positive results, raising fundamental doubts about their reliability (Vickers et al. 1998) and the need of resources for search and translation, this practice will have to change in the future.
In practice, the scrutiny of the literature search will depend strongly on the resources available. Reviews which are based on literature searches in only one or two of the mentioned sources should, however, be interpreted with caution, keeping in mind that a number of relevant studies might have been missed.
A major problem pertinent to systematic reviews is publication bias (Dickersin et al., 1987 and Kleijnen and Knipschild, 1992). Publication bias occurs when studies with undesired results (mostly negative results) are published less often than those with desired results (mostly positive results). Especially small negative or inconclusive studies are less likely to be published. Sometimes authors do not submit such studies; sometimes journal editors reject them. Publication bias typically leads to overly optimistic results and conclusions in systematic reviews.
Reviewers should try to find out whether unpublished studies exist. Informal contacts with researchers in the field are an effective way of achieving this. However, it is often difficult to get written reports on these studies. Handsearching the abstract books and proceedings of research meetings is another potential method of identifying otherwise unpublished studies. Recently, there have been developments that randomized clinical trials are registered beforehand (http://clinicaltrials.gov/ or http://www.controlled-trials.com/). Such registers will probably become the best way in the future to check for unpublished or ongoing studies, but even today many small trials do not become registered.
There are no foolproof ways to detect and quantify publication bias (see section on checking the robustness of results, below, for a method of estimating the influence). Every reviewer and all readers should always be aware of this risk.
Selecting the relevant studies
Selecting the studies for detailed review from the often large number of references identified from the search is the next crucial step in the review process. Readers should check carefully whether this process was transparent and unbiased. Readers should be aware that minor changes in inclusion criteria can result in dramatic differences in the number of included studies in reviews addressing the same topic (Linde & Willich 2003).
A good systematic review of studies on diagnosis or therapy should explicitly define inclusion and exclusion criteria (Box 6.1). It has been outlined above that ‘the question’ of the review already crudely predefines these criteria. In the methods section of a systematic review these criteria should be described in more detail. For example, in a review on garlic for treating hypercholesterinaemia (such as Stevinson et al. 2000), it should be stated at which cholesterol level patients were considered as hypercholesterinaemic. Garlic can be applied in quite different ways (fresh, dried preparations, oil) and we need to know whether all of them were considered (this was not reported explicitly in this specific review).
BOX 6.1
▪ Type of patients/participants (for example, patients with serum cholesterol > 200mg/dl)
▪ Type of studies (for example, randomized double-blind studies)
▪ Type of intervention (for example, garlic mono-preparations in the experimental group and placebo in the control group)
▪ Type of outcomes (for example, trials reporting total cholesterol levels as an endpoint)
▪ Eventually other restrictions (for example, only trials published in English, published in a peer-reviewed journal, no abstracts)
Another selection criterion typically applies to the type of studies considered. For example, many reviews are limited to randomized trials. The measurement and reporting of predefined outcomes as inclusion criteria are of particular relevance when a meta-analysis is planned. This often leads to the exclusion of a relevant proportion of otherwise relevant studies and the reader has to consider whether this might have influenced the findings of the review. Some reviews have language restrictions. This might not only result in the exclusion of a relevant proportion of trials but also change the results (Pham et al. 2005).
In practice the selection process is mostly performed in two steps. In the first step all the obviously irrelevant material is discarded, for example, all articles on garlic which are clearly not clinical trials in patients with cardiovascular problems. To save time and money this step is normally done by only one reviewer in a rather informal way. The remaining articles should then be checked carefully for eligibility by at least two independent reviewers (so that one does not know the decision of the other). In the publication of a systematic review it is advisable to list the potentially relevant studies which were excluded and give the reasons for exclusion. A consensus paper on how meta-analyses should be reported recommends the use of flow charts displaying the number of papers identified, excluded and selected at the different levels of the review and assessment process (Moher et al. 2009). This makes the selection process transparent for the reader.
Extracting information
Finally if a number of eligible studies have been identified, obtained and have passed the selection process, relevant information has to be extracted. If possible the extraction should be standardized, for example, by using a pretested form. The format should allow one to enter the data into a database and to perform basic statistical analyses. Another efficient method is to enter the data directly into a prestructured table. Regardless of what method is used, reviewers have to have a clear idea of what information they need for their analysis and what readers will need to get their own picture. Extraction and all assessments should be done by at least two independent reviewers. Coding errors are inevitable and personal biases can influence decisions in the extraction process. The coded information of the reviewers must be compared and disagreements discussed.
Assessing quality
A major criticism of sceptics towards meta-analysis (and, to a lesser extent, also to non-meta-analytic systematic reviews) is the garbage-in, garbage-out problem. The results of unreliable studies do not become more reliable by lumping them together. It has been shown in conventional and complementary medicine that less rigorous trials tend to yield more positive results (Schulz et al., 1995, Lijner et al., 1999 and Linde et al., 1999). Sometimes it may be better to base the conclusions on a few, rigorous trials and discard the findings of the bulk of unreliable studies. This approach has been called ‘best-evidence synthesis’ (Slavin 1986). While it is sometimes considered as an alternative, it is in principle a subtype of systematic reviews in which defined quality aspects are used as additional inclusion criteria (see White et al. 1997, as an example from complementary medicine).
However, the assessment of quality is difficult. The first problem is that quality is a complex concept. Methodologists tend to define quality as the likelihood that the results of a study are unbiased. This dimension of quality is sometimes referred to as internal validity or methodological quality. But a perfectly internally valid study may have fundamental flaws from a clinician’s point of view if, for example, the outcomes measured are irrelevant for the patients or patients are not representative of those commonly receiving the treatment.
A second problem is that quality is difficult to operationalize in a valid manner. An experienced reviewer will find a lot of subtle information giving an indication on the quality of the study ‘between the lines’ from omissions and small details. However, subjective global ways to assess quality are not transparent and prone to subjective biases.
Many systematic reviews on treatment interventions include some standardized assessments of internal validity. There is agreement that key criteria for the internal validity of treatment studies are random allocation, blinding and adequate handling of dropouts and withdrawals. In the past these and other criteria have typically been combined in scores (see Moher et al., 1995 and Moher et al., 1996 for overviews). But the validity of such scores is doubtful (Jüni et al. 1999). Today it is clearly preferred to assess single validity items without summarizing them in a score, and to investigate whether quality has an impact on findings. Currently, the most important tool is the Cochrane Collaboration’s ‘risk of bias’ assessment (Higgins & Altman 2008). Whether the criteria are combined in scores or applied separately, the problems remain that the formalized assessment is often crude and the reviewers have to rely on the information reported.
In conclusion, assessments of methodological quality are necessary but need to be interpreted with caution. The assessment of other dimensions of quality is desirable, but the problems in the development of methods for this purpose (which have to regard the specific characteristics of the interventions and conditions investigated) are even greater than for internal validity.
Summarizing the results
The clinical reader of a systematic review is mainly interested in its results. While the majority of readers will only look on the abstract and meta-analytic summary, the review also has to provide sufficient information for those who want to get their own idea of the available studies and their results. For example, in a review of acupuncture in headache it will be relevant for the specialist to know what type of headache was studied in each primary study, to have information on the sex and age of the patients, and where they were recruited. Regarding the methods readers should know what the design was, whether there was some blinding, how long the patients were followed and whether follow-up was complete. They need details on the nature of the experimental (which acupuncture points, how many treatments) and the control interventions (type of sham acupuncture). And, of course, readers want to know which outcomes have been measured and what the results were. This detailed information is typically summarized in a table.
If the primary studies provide sufficient data the results are summarized in effect size estimates. Table 6.1 lists some of the most common measures.
| a = number of patients with an event in the experimental group | ||
| b = number of patients without event in the experimental group | ||
| c = number of patients with an event in the control group | ||
| d = number of patients without event in the control group | ||
| xe = mean experimental group | ||
| xc = mean control group | ||
| sd = standard deviations (either of the control group or pooled for both groups) | ||
| Estimate | Calculation | Advantages/disadvantages |
|---|---|---|
| For dichotomous data (e.g. response, death etc.) | ||
| Odds ratio | 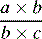 |
Most widespread estimate in epidemiology/intuitively difficult to understand |
| Relative risk (rate ratio) | 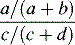 |
Easy to understand/problematic in case of very low or high control group event rates |
| For continuous data (e.g. blood pressure, enzyme activity etc.) | ||
| Weighted mean difference | xe – xc weighted by 1 / variance | Easy to interpret/only applicable if all trials measure the outcomes with the same scale |
| Standardized mean difference | 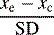 |
Applicable over different scales/clinically difficult to interpret |
Tables including a graphical display of the results are extremely helpful. Table 6.2 shows the standard display from a meta-analysis from the Cochrane Library, in this case on randomized trials comparing hypericum extracts and standard antidepressants (separated in the subgroups older antidepressants and selective serotonin reuptake inhibitors (SSRIs)) in patients with major depression (Linde et al. 2008). For each single study the results in the groups (the number of patients responding and the number of patients allocated to the group) compared are listed in columns two to five. In columns seven and eight the effect size estimates (in this case the ratio between the proportion of patients responding in treatment and control groups) and their respective confidence intervals are presented for each study numerically and graphically. The boxes in the graph indicate the effect size estimates of the single trials while the horizontal lines represent the respective 95% confidence intervals. The diamonds represent the pooled effect size estimates for all trials comparing hypericum extracts and older antidepressants (first diamond), SSRIs (second diamond) and all trials analysed together (third diamond). In the example, effect estimates right of the vertical line (which represents equal responder rates in treatment and control group) indicate superiority of hypericum, those on the left superiority of the control treatment. However, the side representing superiority depends on the outcome measure in other meta-analyses. If the 95% confidence interval does not include the vertical line the difference between treatment and control is statistically significant (P < 0.05).
| Events, number of patients with response; M-H, Mantel–Haenszel method; 95% CI, 95% confidence interval; see text for further explanations. | |||||||
| Study or subgroup | Hypericum | Standard | Risk ratio M-H, random, 95% CI | Risk ratio M-H, random, 95% CI | |||
|---|---|---|---|---|---|---|---|
| Events | Total | Events | Total | Weight | |||
| 4.1.1. vs. older antidepressants | 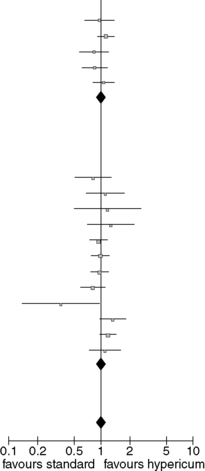 |
||||||
| Harrer 1993 | 27 | 51 | 28 | 51 | 4.3% | 0.96 [0.67, 1.38] | |
| Philipp 1999 | 76 | 106 | 70 | 110 | 12.2% | 1.13 [0.94, 1.36] | |
| Vorbach 1997 | 36 | 107 | 41 | 102 | 4.4% | 0.84 [0.59, 1.20] | |
| Wheatley 1997 | 40 | 87 | 42 | 78 | 5.7% | 0.85 [0.63, 1.16] | |
| Woelk 2000 | 68 | 157 | 67 | 167 | 7.6% | 1.08 [0.83, 1.40] | |
| Subtotal (95% CI) | 508 | 508 | 34.2% | 1.02 [0.90, 1.15] | |||
| Total events | 247 | 248 | |||||
| Heterogeneity: Tau2 = 0.00; Chi2 = 3.97, df = 4 (P= 0.41); I2 = 0% | |||||||
| Test for overall effect: Z = 0.30 (p = 0.77) | |||||||
| 4.1.2 vs. SSRIs | |||||||
| Behnke 2002 | 16 | 35 | 21 | 35 | 2.9% | 0.76 [0.49, 1.20] | |
| Bjerkenstedt 2005 | 22 | 54 | 20 | 54 | 2.6% | 1.10 [0.68, 1.77] | |
| Brenner 2000 | 7 | 15 | 6 | 15 | 0.9% | 1.17 [0.51, 2.66] | |
| Fava 2005 | 17 | 45 | 14 | 47 | 1.8% | 1.27 [0.71, 2.26] | |
| Gastpar 2005 | 70 | 123 | 72 | 118 | 10.2% | 0.93 [0.76, 1.15] | |
| Gastpar 2006 | 71 | 131 | 71 | 127 | 9.6% | 0.97 [0.78, 1.21] | |
| Harrer 1999 | 50 | 77 | 57 | 84 | 9.6% | 0.96 [0.77, 1.19] | |
| HDTSG 2002 | 46 | 113 | 55 | 109 | 6.2% | 0.81 [0.60, 1.08] | |
| Moreno 2005 | 4 | 20 | 11 | 20 | 0.7% | 0.36 [0.14, 0.95] | |
| Schrader 2000 | 57 | 125 | 39 | 113 | 5.3% | 1.32 [0.96, 1.82] | |
| Szegedi 2005 | 86 | 122 | 73 | 122 | 12.2% | 1.18 [0.98, 1.42] | |
| van Gurp 2002 | 25 | 45 | 23 | 45 | 3.8% | 1.09 [0.74, 1.60] | |
| Subtotal (95% CI) | 905 | 889 | 65.8% | 1.00 [0.90, 1.12] | |||
| Total events | 471 | 462 | |||||
| Heterogeneity: Tau2 = 0.01; Chi2 = 15.43, df = 11 (P = 0.16); I2 = 29% | |||||||
| Test for overall effect: Z = 0.06 (P = 0.95) | |||||||
| Total (95% CI) | 1413 | 1397 | 100.0% | 1.01 [0.93, 1.09] | |||
| Total events | 718 | 710 | |||||
| Heterogeneity: Tau2 = 0.00; chi2 = 19.37, df = 16 (P = 0.25); I2 = 17% | |||||||
| Test for overall effect: Z = 0.14 (P = 0.89) | |||||||
Column six gives the weight of each study in the pooled estimate, which depends on sample sizes and variances. The line ‘heterogeneity’ gives indication whether the results of the trials vary more than expected by chance alone. Three measures are given: tau2, the chi2 statistic and I2. For the average reader and researcher I2 is by far the easiest to interpret. An I2-value of 0%, for example, indicates that the differences in the findings of the single trials might well be due to chance while a value above 50% indicates that the trials probably differed in some relevant aspects. Possible reasons for heterogeneity are bias in some trials and variable patient characteristics. Meta-analyses with indication of heterogeneity have to be interpreted with special caution. The P-values in the test of the overall effect are similar to the P-values in trials.
A number of computer programs for systematic reviews and meta-analysis are available. Depending on the type of data and other characteristics of the data (for example, heterogeneity) different statistical techniques are adequate. Although some computer programs allow the novice to perform meta-analyses it is recommended to get guidance or advice from a statistician or an experienced reviewer if pooling of independent studies is an issue.
Checking the robustness of results
If possible, a systematic review should include sensitivity analyses to check the robustness of the results. For example, one can check whether the conclusions would be altered if only studies meeting defined quality criteria were included. Subgroup analyses (for example, on a specific group of trials) can be of value, too, but should be interpreted with caution, particularly if they were not predefined. Unfortunately, a considerable number of primary studies are needed to perform sensitivity and subgroup analyses in a meaningful manner.
Textbooks on systematic reviews recommend to use funnel plots as another means of investigating empirically for biases. A precondition for a funnel plot is a sufficiently large and clinically reasonably homogeneous group of studies (so that a single ‘true’ effect size is a plausible expectation). In funnel plots effect sizes of single studies are plotted against a measure of precision or sample size. The basic idea is that larger studies provide the more reliable estimates of treatment effects as they are less prone to random error (chance variation), within-study bias (larger studies tend to have better internal validity) and publication bias (larger studies are more expensive, known to more people and therefore more likely to be published regardless of the results). If the results of the small studies differ only due to chance variation the resulting graph should resemble an inverted funnel. An asymmetric plot has long been interpreted as an indication of publication bias. However, the concept of ‘small-study effects’, including both elements of publication and within-study bias, is more accurate (Sterne et al. 2001). In any case, both the reviewer and the reader should consider an asymmetric funnel plot a red flag: the findings of the review might be biased!
Who should do systematic reviews?
Many people grossly underestimate the amount of time needed to perform a rigorous systematic review. Protocol development, literature search, extraction, discussion of disagreements in coding and assessments, obtaining missing data from authors and analysing are all time-consuming steps, and a realistic timeline from start to completion of the final report is 12–24 months with repeated periods of intensive work. Of course, it is also possible to make systematic reviews faster but this will probably result in rather superficial work that is of doubtful usefulness.
Until recently, many systematic reviews on complementary medicine have been performed by research methodologists with limited experience on the interventions and conditions investigated. Preferably, the research team for a systematic review should have competency in methodology, intervention and condition under scrutiny to ensure that the results will be both methodologically sound and clinically relevant. As complementary therapies are often controversial and prejudices strong it is desirable to include persons with different prejudices to make the review as balanced as possible. Many steps in retrospective studies like systematic reviews include rather arbitrary decisions which leave space for personal biases to infect the results.
The Cochrane Collaboration is a worldwide network of researchers aimed to perform, regularly update and disseminate systematic reviews of health care interventions (Ezzo et al. 1998). Within the collaboration there is a group focusing on complementary medicine. Researchers who plan to do a systematic review should consider contacting that group (http://www.cochrane.org/). The main challenge for the Cochrane Collaboration is that the resources available for doing reviews are limited and those working on the reviews are to a large extent volunteers. This limits the reviews in several ways. The first is in the number of languages which can be searched and the publications that are evaluated by someone both fluent in the language and expert in systematic reviews. Secondly it limits the resources available both to attain databases to search and in their actual search. Thirdly it greatly affects the amount of grey literature that can be searched. This includes written work such as degree theses, unpublished results from trials, negative results from trials and data collected from agencies such as the US Food and Drug Administration.
An alternative to the Cochrane Collaboration is found in the Evidence-based Practice Centers (EPC) administered by the US Agency for Healthcare Research and Quality (AHRQ) but funded by other agencies, such as the National Center for Complementary and Alternative Medicine (NCCAM). Each EPC is constructed slightly differently and each must compete annually for contracts to produce evidence reports for the government agency, or on occasions, for third-party organizations (Coulter 2007). From 2000 to 2003 NCCAM through AHRQ established an EPC for CAM.
The greatest difference between these centres and the Cochrane Collaboration is in resources such as funding. Coulter (2007) has shown that, in their study of Ayurvedic medicine for the treatment of diabetes mellitus, done at the Southern California EPC, the project was able to visit the major research centres in India, access and purchase Indian journals, and review theses in their native language. In the final systematic review, 35 studies CAMe from the western literature and 27 CAMe from the Indian literature. Of those on which statistical analysis was performed 12 were from India and only eight from western literature. So the Indian literature had a great influence on the systematic review. This is not unusual for CAM where many of the systems (traditional Chinese medicine, Ayurvedic medicine, homeopathy, yoga, acupuncture) are not systems that originated in the west and often have a very long published history in languages other than English. So systematic reviews that confine their reviews to English only run the risk of missing important evidence. However it is not practical to expect that the EPCs will be able to conduct the number of systematic reviews that are produced by the Cochrane collaboration and by other means. The work of the EPCs is available online at (http://www.ahrq.gov/clinic/epcix.htm) as evidence reports.
How to identify existing systematic reviews
The most relevant sources to identify existing systematic reviews are PubMed (http://www.ncbi.nlm.nih.gov/sites/entrez?db=pubmed) and the Cochrane Library (http://www.cochrane.org/). By using the term ‘systematic reviews’ as ‘subset’ in the menu ‘limits’ or the term ‘meta-analysis’ as ‘publication type’ in the same menu, and combining it with the clinical problem of interest, PubMed can be searched efficiently. The search for the ‘subset systematic reviews’ will identify a larger number of articles (for example, a search for hypericum yielded 72 hits in January 2010), including meta-analyses, systematic reviews without pooling and a number of other papers resembling systematic reviews. The search for the ‘publication type meta-analysis’ will yield a more selected group of systematic reviews and meta-analyses but may miss a few relevant articles (in case of the hypericum search it yielded 18 hits).
The Cochrane Library an online resource (http://www.thecochranelibrary.com) produced by the above-mentioned Cochrane Collaboration. It contains the full text of all reviews performed by the network as well as references and abstracts of a large number of other systematic reviews.
Limitations of systematic reviews
Clearly, although systematic reviews are of utmost importance, they are prone to a number of biases. Even the best systematic review will be of limited value if the primary studies are flawed. It has been shown that the findings of very large clinical trials (which are considered as the ultimate gold standard to assess the merit of a treatment) differ in a considerable number of cases from those of meta-analyses on the same topic (Lelorier et al. 1997). The large number of decisions in a systematic review can also have a relevant impact on the results. As a consequence it should not be surprising that systematic reviews performed by different research groups sometimes come to conflicting conclusions (see Linde & Willich 2003 for a review).
Readers should check reviews carefully. Guidelines for critical appraisal are available (see references for further reading). Box 6.2 lists a number of questions to consider when reading systematic reviews. Systematic reviews cannot replace original research. Particularly in complementary medicine, their conclusiveness will remain limited unless new, reliable primary studies become available.
BOX 6.2
▪ Was there a clearly defined question?
▪ Was the literature search comprehensive?
▪ Were inclusion and exclusion criteria defined and adequate?
▪ Was bias avoided in the process of selecting studies for inclusion in the review from the body of literature identified?
▪ Was the quality of the included studies assessed using relevant criteria?
▪ Have patients, methods, interventions and results of the included studies been described in sufficient detail?
▪ If the review included a meta-analysis, were the methods used adequate and the primary studies sufficiently comparable?
▪ Have the shortcomings of the review been discussed?
▪ Are the results relevant to clinical practice?
As this article has noted, each step of the systematic review poses questions that must be asked by the reader to assess whether the review was rigorous, comprehensive, inclusive and valid (Coulter 2006). The search and hence the conclusions can be biased at many points and, like many other methods, with systematic reviews, if you put garbage in, you get garbage out.
But there are other major issues that must caution the current use of systematic reviews for CAM. Maybe the most important issue is their often questionable external validity and clinical relevance. Most available CAM reviews are restricted to RCTs and exclude observational studies. However, RCTs of CAM interventions often reflect very little how the treatment is actually used in practice. For example, in homeopathy three-quarters of the available randomized trials investigate standardized treatment interventions, although individualization is a cornerstone of this therapy (Shang et al. 2005). Traditional healing systems like Chinese medicine normally use complex interventions such as a combination of acupuncture, moxibustion, herbal medicines, and manipulative or relaxation techniques, whereas randomized trials in this area are typically limited to one component such as acupuncture or a standardized combination of herbs. Furthermore, many trials use sham or placebo controls to investigate ‘specific’ effects in often artificial conditions. Randomized trials investigating whole systems in a pragmatic manner and comparing with realistic alternatives are extremely rare.
Furthermore, for the foreseeable future the number of RCTs done in CAM will continue to lag well behind those in allopathic medicine. For much of CAM there is no interest in, or profit in, pharmaceutical companies funding such trials. Issues such as property rights for indigenous healing traditions have made this less attractive for such research. Moreover, the practice of CAM does not favour the development and use of the ‘magic bullets’ of single active drugs and allopathic medicine has shown some antipathy to using CAM products. The amount of public research funding for CAM is miniscule. The USA is spending by far the most of all western countries for CAM research, but still the budget of the relevant institute (the NCCAM) for 2006 was only 0.42% of the total National Institutes of Health budget (National Institutes of Health 2007). Simply put, there is neither enough funding nor enough effort being put into conducting RCTs on CAM and there will not be for some time to come.
High-quality observational studies could greatly contribute to the evidence base on CAM, and discrediting such studies in favour of randomized trials is inappropriate. There is an expanding body of literature on studies examining RCTs and observational studies for the same disease and intervention. Earlier studies concluded that non-randomized studies overestimated treatment benefits. More recently, the studies show that both randomized and non-randomized studies yield very similar results (for example, Benson and Hartz, 2000, Concato et al., 2000 and Linde et al., 2007). Some studies have found little evidence of a difference in the treatment effects between RCTs and observational studies when the comparisons were made for the same treatment. The results of well-designed observational studies did not systematically exaggerate the magnitude of the effects of treatment compared to the RCTs for the same topic (Coulter 2006).
While efficacy is important, ultimately it is effectiveness that we wish to know about in truly evidence-based practice. It is effectiveness, not efficacy, studies that provide evidence of how a therapy will work in real practice. In fact there is an urgent need to put the practice back into practice-based medicine (Coulter 2007). The very studies that improve the quality of systematic reviews, that is, placebo-controlled RCTs, deal with efficacy and not effectiveness. Because they tend to be conducted under artificial conditions they seldom provide the type of information needed to make a decision vis-à-vis an individual patient. Well-designed observational studies could provide much better information in this regard.
In some areas of CAM most studies are observational. While randomized trials in CAM often suffer from relevant shortcomings, the quality of many observational studies is even worse. There is a clear need to improve and develop observational studies in CAM. The challenge for reviewers is to develop standards for judging the quality of observational studies. Reviewers should also follow guidelines for reporting meta-analyses of observational studies (Stroup et al. 2000).
We can also note that whole areas of evidence, such as health services research and programme evaluation, tend to be left out of systematic reviews (Coulter & Khorsan 2008). Such work, which is based on real-world practice, adds an element of reality to evidence-based research.
We would be incomplete if we did not mention other approaches to systematic review and meta-analysis besides those described here. Of particular interest may be those from the educational and behavioural literature that also evaluate complex interventional treatments and research. These methods may provide a better approach to heterogeneous studies that allow for valid conclusions (see Jonas et al. 2001 for an example). The value of this approach is that it can manage complex and heterogeneous aspects of interventional research, and yet still come up with what is considered valid conclusions. These should be considered and further developed in CAM and whole systems research.
How should we use systematic reviews in CAM?
Clearly the answer is: cautiously but, that being noted, systematic reviews can provide some very useful functions for CAM. Firstly they are excellent sources for reviewing the state of the science. They can and do draw attention to methodological weaknesses in the quality of evidence which arises from the quality of the research. They have established the lack of good-quality, rigorous trials in CAM. Such studies have also shown that some of the attributed ‘quality differences’ arise when you compare CAM and whole systems research with approaches to drug research. This is not simply differences in quality but differences in research methodology which make it inappropriate to use terms such as ‘superior’ or ‘inferior’. They are simply different (Crawford et al. 2009). Secondly they do review adverse events (usually through case reports) and make risk/benefit assessments. Thirdly they provide a clearing ground for basic questions and allow us to move on to more important second-order questions. So, for example, if systematic reviews can establish that acupuncture, manipulation, yoga and homeopathy have some efficacy, then the research agenda can be moved to the more significant questions of: for what type of patients, for what health problems and in whose hands does the therapy achieve the best results? In a metaphorical sense this could be considered the equivalent of a gardener clearing the undergrowth to get at the good plants.
In those areas where good systematic reviews of CAM are available we can move towards more evidence-based practice but also move towards determining clinical applications and to new research questions such as the rate of appropriate and inappropriate practice. The early work at RAND on manipulation for low-back pain (Coulter et al. 1995) led to a systematic review and a meta-analysis. An expert panel was then set up and a set of indications based on both the systematic review and clinical experience was created for the use and non-use of manipulation for low-back pain. This in turn led to a field study in which the rate of chiropractic appropriate and inappropriate manipulation for low-back pain was established (Coulter 2001). While it showed on the one hand that 27% of patients were inappropriately manipulated, it also showed that 41% were candidates for manipulation but were not manipulated (Coulter et al., 1995 and Coulter, 2001). Such research, if repeated across CAM, could establish whether or not inappropriate care (one of the dominant concerns by allopathic medicine and funding health care agencies about CAM) is a problem. Furthermore, systematic reviews are often precursors to the development of consensus conferences and guidelines.
In summary, systematic reviews are somewhat like the curate’s egg: parts of it are excellent, the rest, not so good. More training and application of a variety of systematic review approaches should be developed and applied to CAM.
References
Benson, K.; Hartz, A.J., A comparison of observational studies and randomized, controlled trials, N. Engl. J. Med. 342 (2000) 1878–1886.
Concato, J.; Shah, N.; Horwitz, R.I., Randomized, controlled trials, observational studies, and the hierarchy of research designs, N. Engl. J. Med. 342 (2000) 1887–1892.
Coulter, I.D., Evidence based complementary and alternative medicine: promises and problems, Forsch. Komplementarmed. 14 (2007) 102–108.
Coulter, I.D., Evidenced-based practice and appropriateness of care studies, J. Evid. Based Dent. Pract. 1 (2001) 222–226.
Coulter, I.D., Evidence summaries and synthesis: necessary but insufficient approach for determining clinical practice of integrated medicine?Integr. Cancer Ther. 5 (2006) 282–286.
Coulter, I.D., Putting the practice into evidence-based dentistry, CDAJ 35 (2007) 45–49.
Coulter, I.D.; Khorsan, R., Is health services research the holy grail of CAM research?Altern. Ther. Health Med. 14 (2008) 40–45.
Coulter, I.D.; Shekelle, P.; Mootz, R.; et al., The use of expert panel results: The RAND Panel for Appropriateness of Manipulation and Mobilization of the Cervical Spine, J. Topics in Clinical Chiropractic 2 (3) (1995) 54–62.
Crawford, C.C.; Huynh, M.T.; Kepple, A.; et al., Assessment of the quality of research studies of conventional and alternative treatment(s) of primary headache, Pain Physician (2009); 12, 461–470.
Dickersin, K.; Chan, S.; Chalmers, T.C.; et al., Publication bias and clinical trials, Contr. Clin. Trials 8 (1987) 343–353.
Ernst, E., Iridology: a systematic review, Forsch. Komplementärmed. 6 (1999) 7–9.
Ezzo, J.; Berman, B.M.; Vickers, A.J.; et al., Complementary medicine and the Cochrane Collaboration, JAMA 280 (1998) 1628–1630.
Higgins, J.P.T.; Altman, D.G., Chapter 8: Assessing risk of bias in included studies, In: (Editors: Higgins, J.P.T.; Green, S.) Cochrane Handbook for Systematic Reviews of Interventions Version 5.0.1 (updated September 2008) (2008) The Cochrane Collaboration; Available fromwww.cochrane-handbook.org.
Jonas, W.B.; Anderson, R.L.; Crawford, C.C.; et al., A systematic review of the quality of homeopathic clinical trials, BMC Complement. Altern. Med. 1 (2001); Document 12.
Jüni, P.; Witschi, A.; Bloch, R.; et al., The hazards of scoring the quality of clinical trials for meta-analysis, JAMA 282 (1999) 1054–1060.
Kleijnen, J.; Knipschild, P., Review articles and publication bias, Arzneim-Forsch/Drug Research 42 (1992) 587–591.
Knüppel, L.; Linde, K., Adverse effects of St. John’s wort: a systematic review, J. Clin. Psychiatry 65 (2004) 470–479.
LeLorier, J.; Grégoire, G.; Benhaddad, A.; et al., Discrepancies between meta-analysis and subsequent large randomized, controlled trials, N. Eng. J. Med. 337 (1997) 536–542.
Lijner, J.G.; Mol, B.W.; Heisterkamp, S.; et al., Empirical evidence of design-related bias in studies of diagnostic tests, JAMA 282 (1999) 1061–1066.
Linde, K.; Willich, S., How objective are systematic reviews? Differences between reviews on complementary medicine, J. R. Soc. Med. 96 (2003) 17–22.
Linde, K.; Schulz, M.; Ramirez, G.; et al., Impact of study quality on outcome in placebo-controlled trials of homeopathy, J. Clin. Epdemiol. 52 (1999) 631–636.
Linde, K.; Vickers, A.; Hondras, M.; et al., Systematic reviews of complementary therapies – an annotated bibliography. Part I: Acupuncture, BMC Complement. Altern. Med. 1 (2001); Document 3.
Linde, K.; Jonas, W.B.; Melchart, D.; et al., The methodological quality of randomized controlled trials of homeopathy, herbal medicine and acupuncture, Int. J. Epidemiol. 30 (2001) 526–531.
Linde, K.; Streng, A.; Hoppe, A.; et al., Randomized trial vs. observational study of acupuncture for migraine found that patient characteristics differed but outcomes were similar, J. Clin. Epidemiol. 60 (2007) 280–287.
Linde, K.; Berner, M.; Kiston, L., St John’s wort for major depression, Cochrane Database Syst. Rev. (4) (2008); CD000448.
Moher, D.; Jadad, A.R.; Nichol, G.; et al., Assessing the quality of randomized controlled trials: an annotated bibliography of scales and checklists, Control. Clin. Trials 16 (1995) 62–73.
Moher, D.; Jadad, A.R.; Tugwell, P., Assessing the quality of randomized controlled trials – current issues and future directions, Int. J. Technol. Assess. Health Care 12 (1996) 196–208.
Moher, D.; Liberati, A.; Tetzlaff, J.; et al., Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement, PLoS Med. 6 (2009); e1000097.
Mulrow, C.D., Rationale for systematic reviews, In: (Editors: Chalmers, I.; Altman, D.G.) Systematic reviews (1995) BMJ Books, London, p. 1.
National Institutes of Health. Summary of the FY, In: Presidents Budget (2007), p. 9;http://officeofbudget.od.nih.gov/pdf/Press%20info%20final.pdf.
Pham, B.; Klassen, T.P.; Lawson, M.L.; et al., Language of publication restrictions in systematic reviews gave different results depending on whether the intervention was conventional or complementary, J. Clin. Epidemiol. 58 (2005) 769–776.
Schulz, F.K.; Chalmers, I.; Hayes, R.J.; et al., Empirical evidence of bias: dimensions of methodological quality associated with estimates of treatment effects in controlled trials, JAMA 273 (1995) 408–412.
Seely, D.; Mills, E.J.; Wu, P.; et al., The effects of green tea consumption on incidence of breast cancer and recurrence of breast cancer: a systematic review and meta-analysis, Integr. Cancer Ther. 4 (2005) 144–155.
Shang, A.; Huwiler-Müntener, K.; Nartey, L.; et al., Are the clinical effects of homoeopathy placebo effects? Comparative study of placebo-controlled trials of homoeopathy and allopathy, Lancet 366 (2005) 726–732.
Slavin, R.E., Best-evidence synthesis: an alternative to meta-analysis and traditional reviews, Educational Research 15 (1986) 9–11.
Sterne, J.A.C.; Egger, M.; Davey Smith, G., Investigating and dealing with publication and other bias, In: (Editors: Egger, M.; Davey Smith, G.; Altman, D.G.) Systematic reviews in healthcare: meta-analysis in context (2001) BMJ Books, London, pp. 189–208.
Stevinson, C.; Pittler, M.H.; Ernst, E., Garlic for treating hypercholesterinemia. A meta-analysis of randomized controlled clinical trials, Ann. Intern. Med. 133 (2000) 420–429.
Stroup, D.F.; Berlin, J.A.; Morton, S.C.; et al., Meta-analysis of observational studies in epidemiology: a proposal for reporting. Meta-analysis Of Observational Studies in Epidemiology (MOOSE) group, JAMA 283 (2000) 2008–2012.
Verhoef, M.J.; Balneaves, L.G.; Boon, H.S.; et al., Reasons for and characteristics associated with complementary and alternative medicine use among adult cancer patients: a systematic review, Integrat. Cancer Ther. 4 (2005) 274–286.
Vickers, A.; Goyal, N.; Harland, R.; et al., Do certain countries produce only positive results? A systematic review of controlled trials, Control. Clin. Trials 19 (1998) 159–166.
Wang, G.; Mao, B.; Xiong, Z.Y.; et al., The quality of reporting of randomized controlled trials of traditional Chinese medicine: a survey of 13 randomly selected journals from mainland China, Clin. Ther. 29 (2007) 1456–1467.
White, A.R.; Resch, K.L.; Ernst, E., Smoking cessation with acupuncture? A ‘best evidence synthesis’, Forsch. Komplementärmed. 4 (1997) 102–105.
Xie, Y.; Wang, L.; He, J.; et al., Acupuncture for dysphagia in acute stroke, Cochrane Database Syst. Rev. (3) (2008); CD006076.
Further reading
Borenstein, M.; Hedges, L.V.; Higgins, J.P.T.; et al., Introduction to Meta-Analysis. (2009) Wiley, Chichester.
In: (Editors: Cooper, H.; Hedges, L.V.) The handbook of research synthesis (1994) Russel Sage Foundation, New York.
In: (Editors: Egger, M.; Davey Smith, G.; Altman, D.G.) Systematic reviews in healthcare: meta-analysis in context (2001) BMJ Books, London.
In: (Editors: Higgins, J.P.T.; Green, S.) Cochrane Handbook for Systematic Reviews of Interventions Version 5.0.1 (updated September 2008) (2008) The Cochrane Collaboration; Available online fromwww.cochrane-handbook.org.
Leandro, G., Meta-analysis in Medical Research: The handbook for the understanding and practice of meta-analysis. (2005) BMJ Books, London.