[level-membership-for-pediatrics-category]
Evidence-Based Medicine
‘In God we trust; all others must bring data.’
—W. EDWARDS DEMING, PHYSICIST AND QUALITY IMPROVEMENT PIONEER
Evidence-based medicine (EBM) is defined as the conscientious, explicit, and judicious use of the current best evidence in making decisions about the care of individual patients.1 A simpler concept would be treating patients based on data rather than the surgeon’s thoughts or beliefs. EBM represents the concept that medical practice can be largely dictated by evidence gained from the scientific method. Given that the practice of medicine has historically been based on knowledge handed down from mentor to apprentice, the concepts of EBM embody a new paradigm, replacing the traditional paradigm that was based on authority. In a global sense, it describes a methodology for evaluating the validity of clinical research and applying those results to the care of patients.
History
The initial groundwork forming the framework for EBM can be considered the earliest scientists who pursued explanatory truth instead of accepting beliefs. The process of discovering truth became replicable for aspiring scientists when the scientific method was developed. No one individual can be credited for creating the scientific method because it is the result of the progressive recognition for a natural process of acquiring facts. However, the earliest publication alluding to the steps of current scientific methodology may be found in Book of Optics published in 1021 by Ibn al-Haytham (Alhazen).2 His investigations were based on experimental evidence. Furthermore, his experiments were systematic and repeatable as he demonstrated that rays of light are emitted from objects rather than from the eyes. In Western literature, Roger Bacon wrote about a repeating cycle of observation, hypothesis, and experimentation in the 1200s. Influenced by the contributions of many scientists and philosophers, Francis Bacon delineated a recognizable form of the scientific method in the 1620 publication of Novum Organum Scientificum.3 He suggested that mastery of the world in which man lives is dependent on careful understanding. Moreover, this understanding is based entirely on the facts of this world and not, as the ancients portrayed it, in philosophy. Nearly 400 years later, we find ourselves coming to the same conclusions in the practice of medicine and surgery. We now understand that facts and truths transcend experience, and that facts about optimal care can be gained through experimentation more reliably than from beliefs generated through experience.
The establishment of the scientific method in the pursuit of proven truths was fundamental to the development of EBM as an entity. The current scientific method consists of several steps that are outlined in Box 78-1. However, the concepts of EBM are not simply encompassed by the application of these steps to attain facts, but also address the ability to understand the value of the results generated from experimentation. Under the auspices of EBM, investigators are burdened with the first five steps, from inquiry to experimentation, while all caregivers must develop a deep understanding of experimental methodology, analysis of data, and how conclusions are drawn to be able to place appropriate value on published studies to influence their practice.
The movement urging physicians to utilize proven facts in the development of decision-making algorithms began in 1972 with the publication of the revolutionary book Effectiveness and Efficiency: Random Reflections on Health Services.4 The author, Archie Cochrane, a Scottish epidemiologist working in the UK National Health Service, has likely had the greatest influence on the development of an organized means of guiding care through data and results. The book demonstrates disdain for the scientific establishment, devalues expert opinion, and shows that physicians should systematically question what is the best care for the patient. Most impressively, Cochrane calls for an international registry of randomized controlled trials and for explicit quality criteria for appraising published research. At the time of his passing in 1988, these aspirations had not fully materialized. However, the field of medicine is fortunate that Cochrane’s prophetic ideas have precipitated the maturation of centers of EBM research that make up the global not-for-profit organization called the Cochrane Collaboration. The product of this collaboration is The Cochrane Library, which is a collection of seven databases that contain high-quality, independent evidence to inform health care decision-making.5 The most clinically utilized database is the Cochrane Database of Systematic Reviews containing reviews on the highest level of evidence on which to base clinical treatment decisions. There are now over 550,000 entries.
After Cochrane and other proponents of EBM showed the importance of comparative data, it took over a decade for the amorphous clouds of these concepts to solidify into tangible terms and usable methods. The methodology of specifically qualifying data and judging the relative merits of available studies did not begin to appear in the literature until the early 1990s. In a paper published in 1990 by David Eddy on the role of guidelines in medical decision-making, the term evidence-based first appeared in the literature.6 Much of the framework currently used to determine best available evidence was established by David Sackett and Gordon Guyatt at the McMaster University-based research group called the Evidence-Based Medicine Working Group. In 1992, JAMA published the group’s landmark paper titled, ‘Evidence-Based Medicine: A New Approach to Teaching the Practice of Medicine,’ and the term evidence-based medicine was born.7 A cementing moment in the paradigm shift occurred when the Centre for Evidence-Based Medicine was established in Oxford, England, in 1995 as the first of several centers. Over the past decade, centers or departments focusing on clinical research and EBM have been developed at universities and hospitals around the world, including our own (www.cmhclinicaltrials.com). EBM principles are now represented in the core curriculum that is integral to three of the six general competencies outlined by the Accreditation Council for Graduate Medical Education that oversees the accredited residency training programs in the United States. The concept of EBM is no longer a movement of progressive physicians, but rather a basic guiding principle of medical training and practice.
Levels of Evidence
Level 1—evidence is supported by prospective, randomized trials
Level 2—evidence is supported by cohort studies, outcomes data, or low-quality prospective trials
Level 3—evidence comprises case-control studies
Level 4—evidence is based on case series
Level 5—evidence is expert opinion or beliefs based on rational principles.
The quality of data that is conveyed within each level and study type is clearly a wide spectrum. The complete delineation in the levels of evidence as defined by the Oxford Centre for Evidence-Based Medicine is outlined in Table 78-1.
TABLE 78-1
Levels of Evidence as Defined by the Oxford Centre for Evidence-Based Medicine
| Level | Type of Evidence |
| 1a | Systematic review of randomized trials displaying homogeneity |
| 1a− | Systematic review of randomized trials displaying worrisome heterogeneity |
| 1b | Individual randomized controlled trials (with narrow confidence interval) |
| 1b− | Individual randomized controlled trials (with a wide confidence interval) |
| 1c | All or none randomized controlled trials |
| 2a | Systematic reviews (with homogeneity) of cohort studies |
| 2a− | Systematic reviews of cohort studies displaying worrisome heterogeneity |
| 2b | Individual cohort study or low-quality randomized controlled trials (<80% follow-up) |
| 2b− | Individual cohort study or low-quality randomized controlled trials (<80% follow-up/wide confidence interval) |
| 2c | ‘Outcomes’ research; ecological studies |
| 3a | Systematic review (with homogeneity) of case-control studies |
| 3a− | Systematic review of case-control studies with worrisome heterogeneity |
| 3b | Individual case-control study |
| 4 | Case series (and poor quality cohort and case-control studies) |
| 5 | Expert opinion without explicit critical appraisal, or based on physiology, bench research, or ‘first principles’ |
As can be seen by the levels listed in Table 78-1, the strength of evidence improves significantly by the application of prospective data collection. In clinical medicine, and particularly in the practice of surgery, many aspects of trial design are not feasible such as blinding, placebo treatments, independent follow-up evaluation, and others. However, if one accepts these limitations and conducts a trial with prospective evaluation, the results remain markedly more meaningful than a retrospective case-control comparative series that compares surgeons and/or timeframes against one another.
The review of several studies can gain strength over an individual study, which is valid in many models and fields of medicine. However, one should be cautioned about the real strengths of such a meta-analysis before considering it to have a high level of evidence. The strength of these combined reviews is derived from the strength of the individual trials providing the numbers for the analysis. In the best scenario, such a combined review is composed of multiple prospective trials with similar design that each compares the effect of two treatments on a specific outcome. However, in the field of pediatric surgery, multiple prospective trials with similar designs that address the same disease with the same interventions are nonexistent. Also, surgeons should not overvalue the influence of combined reviews derived from retrospective studies. Such reviews should be interpreted as a mosaic of the individual studies. Any attempt by authors to combine a number of retrospective studies to harness statistical power is fraught with hazard.
Grades of Recommendation
The quality of the evidence as defined in Tables 78-1 and 78-2 applies a score of strength for each individual contribution in the literature. However, on many topics, particularly common clinical scenarios, there is an abundance of published studies such that the appropriate care cannot be guided by a single study. The total body of available information places caregivers in the difficult position of evaluating the published principles from the multiple sources that make up practice guidelines. The caregiver applying these clinical practice guidelines and other recommendations needs to know how much confidence can be placed in the recommendations from a conglomerate of citations. Strength of recommendation scales were born from this need.8–12 Given that the level of evidence indicates the extent to which one can be confident that an estimate of effect is correct, the strength or grade of recommendation indicates the extent to which one can be confident that adherence to the recommendation will do more good than harm.13 As with the levels of evidence, there are multiple published grading scales. The grading format used by the Oxford Centre for Evidence-Based Medicine is outlined in Table 78-2.
TABLE 78-2
Grades of Recommendation as Defined by the Oxford Centre for Evidence-Based Medicine
| Grade | Level of Evidence |
| A | Consistent level 1 studies |
| B | Consistent level 2 or 3 studies or extrapolations from level 1 studies |
| C | Level 4 studies or extrapolations from level 2 or 3 studies |
| D | Level 5 evidence or troublingly inconsistent or inconclusive studies of any level |
The levels of evidence are more easily assessed because each contribution falls into a given level based on study design. However, establishing the grade of recommendation can be more complex given the fact that multiple levels of evidence from different timeframes invariably exist on any given clinical topic. This is further confusing because many disease processes have multiple outcome measures. Also, each treatment option can affect different outcomes in independent ways that must be balanced against the risk or toxicity of each treatment. A working group has outlined a process for establishing grade based on the following sequential steps:14
1. Assess the quality of evidence across studies for each important outcome
2. Decide which outcomes are critical to a decision
3. Judge the overall quality of evidence across these critical outcomes
At this time, an accepted standard for respecting the level of evidence and assessing grades of recommendation is lacking in the pediatric surgery field.
Landscape of Pediatric Surgery
The future of care being directed by comparative research is brightening. There has historically been a great focus on basic science research when resource allocation is considered. However, despite the fact that government funding for basic science has far exceeded clinical research, the impact on clinical care relative to the investment has been low. The National Institutes of Health (NIH) is beginning to place greater emphasis on comparative effectiveness research versus classic basic science investigations. The Obama administration has recently approved $400M of funds to the NIH, while the Agency for Healthcare Research and Quality (AHRQ) received $300M from the Recovery Act legislation in addition to $400M that can be used at the discretion of the Secretary of Health for comparativeness effectiveness research.15 Comparative effective research is defined by AHRQ as research designed to inform health care decisions by providing evidence on the effectiveness, benefits, and harms of different treatment options. The evidence is generated from research studies that compare drugs, medical devices, tests, operations, or ways to deliver health care.
Retrospective Studies
As our field is overly represented with retrospective comparisons, it is important to recognize the natural flaws introduced by retrospective analysis. At least one of two confounding factors is present when an institution reviews and compares different therapies retrospectively. When an institution is concurrently using different treatment plans, usually the comparison between treatment plans also compares caregivers. The other possibility is that the center has changed treatment plans and then retrospectively investigates the effect of this change. Although this sounds attractive, it becomes a comparison between timeframes. Historical comparison groups are difficult to use with confidence because of the rapid ongoing changes in hospital systems. Many institutions have quality assurance programs that intend to make all patient care more consistent and efficient. Such change will impact outcomes regardless of the surgical treatment. A universal concern with retrospective studies is the assurance of reviewing the entire population and the entire dataset. It can be very difficult to accurately identify all the data desired when retrospectively collecting information. As a result, datasets are often incomplete, which decreases scientific confidence. Another issue, rarely acknowledged in retrospective studies, is the difficulty with capturing the entire population intended for study. There are many coding nuances within an institution that may exclude patients from lists when the database is searched by ICD-9 code. A specific type of patient, such as a treatment failure, can go undetected, because of being hidden under a different diagnosis code. This can create tremendous error in the published data.
Considerations for Prospective Trials in Pediatric Surgery
Although it is clear that prospective trials offer the highest scientific integrity and the best vehicle for determining superior efficacy among options, they have been underutilized in the field of surgery, and specifically, pediatric surgery. Critics have postulated that consented prospective trials would have a limited role in pediatric surgery because parents would be unwilling to enroll their children into such studies. Studies should not be conducted in any human population when there is substantial risk of harm balanced against questionable benefit. A well-designed study should offer patients the potential for a better outcome than the standard means of treatment outside the study. However, there is no example in the published literature to support the speculation that studies should not be attempted in children. Moreover, there are now several prospective, randomized trials being conducted and emerging in the pediatric surgery literature that would suggest otherwise.16–24
Equipoise
There is usually a role for a trial when equipoise exists for the currently available therapeutic options. Equipoise is the assumption that two treatment plans are equal. Thus, the trial simply pits the two options head to head to identify which is superior. Each caregiver participating in a study does not need to possess true inherent equipoise without bias. Naturally, each practitioner will have biases and suppositions about which management strategy is superior, but there remains a role for a trial when each caregiver can honestly acknowledge that there is not enough evidence to prove his or her own thoughts are correct. The most obvious examples of the need for a trial are circumstances in which more than one management strategy is utilized in a given institution. This usually occurs due to caregiver bias. An example would be the use of irrigation during laparoscopic appendectomy for perforated appendicitis.16 Most surgeons will believe in one or the other, but not both. Another would be tube thoracostomy and fibrinolysis versus thoracoscopic decortication for empyema.17,18 If a given patient condition is treated by pathway A or B based simply on the caregivers who were on call and there is no evidence to support either pathway, then not only is there a role for a trial, but, in reality, there is an ethical need to conduct such a study to prevent the potential tragedy wherein half of the patients are receiving inferior care simply due to bias without evidence.25
Patient Volume
The conduction of a study requires adequate patient volume, which is not a concern for common conditions. However, acquisition of good evidence has long been difficult in pediatric surgery owing to the wide variety of individually rare conditions. When considering less common conditions, physicians often simply suggest expanding the number of institutions participating in a trial to overcome volume limitations. This is the common answer, but is difficult to implement because each additional institution will need to take on a significant workload. Moreover, not all surgeons at each institution will be invested in the study and therefore may not adhere to the study design. Also, depending on the nature of the study, not all surgeons may be able to offer treatment in both arms. For instance, one of the reasons that a prospective randomized trial failed in comparing open and minimally invasive approaches for cancer in the mid-1990s was because very few of the surgeons could perform the required minimally invasive surgical procedures.26 It remains a fact that the integrity of the study will decrease with the addition of more institutions and more caregivers because it is less likely the protocols will be followed completely.
Outcomes Research
Outcomes research is the analysis of outcomes and their predictors at different levels in the health care delivery system.27 The critical difference between clinical trials research and outcomes or database research is the scope of view as depicted in Figure 78-1.28 Clinical trials set inclusion criteria to create a desired population most likely to answer the question of interest. Thus, the patients are defined from the outset. Outcomes research uses all patients in the database. Clinical trials control for patient differences by randomization. In outcomes research, however, one can control for differences only in the analysis models. While some may argue outcomes research provides a better answer that is generalizable to the practicing community, the inability to sort out patients with confounding variables makes outcomes research more practical in addressing national, regional, and hospital trends where the view of individual patient management becomes blurred. Clinical trials provide more a clear picture to answer specific management questions. However, outcomes research can be utilized to benchmark quality of care, compare therapeutic effectiveness, refine management strategies, provide patient education, and produce important marketing information.28
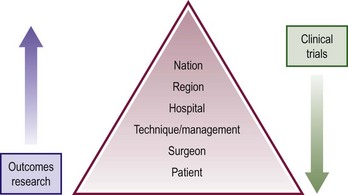
FIGURE 78-1 This figure depicts the differing focus between outcomes research and clinical trials. Outcomes research provides a top down view with more strength at the top of the pyramid while clinical trials provide a more clear focus at the patient and management level.
Administrative Databases
Administrative databases are typically large computerized data files compiled for billing purposes. The data is gathered by billing coders and not clinicians, and are mostly based on ICD-9 coding systems. The ICD-9 coding system has a separate diagnosis code as well as a separate procedure code. Of the administrative databases, the National Inpatient Sample (NIS) is the most generalized database.29 There are other subspecialty databases publicly available for trauma, oncology, and transplant. The Kids’ Inpatient Database (KID) is a weighted pediatrics sample that is an all-payer inpatient care database for children in the USA.30 It is released every 3 years. The KID database is de-identified, but includes unique provider and hospital codes that allows for hospital-level analysis and can be linked to other databases containing other non-medical information. The Child Healthcare Corporation of America (CHCA) maintains the Pediatric Health Information Systems (PHIS) database which currently collects billing data from 44 tertiary referral children’s hospitals in the USA.
There are disadvantages to these databases. They contain only inpatient data with limited clinical course information, limiting the ability to follow a patient’s course upon discharge. Additionally, it can be difficult to determinate the timing of the diagnoses.28
Clinical Databases
Clinical databases, on the other hand, are populated through a clinician reviewer. The most well-known and utilized clinical database is the American College of Surgeons-National Surgical Quality Improvement Program (ACS-NSQIP).31
In 2005, a children’s NSQIP module was developed. The pediatric NSQIP module’s starting algorithm section is 35 major cases every eight days on patients <18 years of age, rotating on each subsequent week day.32 There are 121 data points from most surgical specialties within the pediatric module compared to 135 in the adult NSQIP. These include demographics, hospitalization characteristics, and complications with additional data points for neonates. Outcomes for both adult and pediatric NSQIP modules are assessed for 30 days following the procedure.
Adult and pediatric trauma patients are tracked by the National Trauma Data Bank (NTDB), which includes 900 trauma centers.33 Adult and pediatric malignancies are maintained in the Surveillance, Epidemiology, and End Results (SEER) database, which is maintained by National Cancer Institute.34 The SEER registries routinely collect data on patient demographics, primary tumor site, tumor morphology and stage at diagnosis, first course of treatment, and follow-up status. The mortality data reported by SEER is provided by the National Center for Health Statistics. The American College of Surgeons Committee on Cancer maintains the National Cancer Data Base (NCDB) containing adult and pediatric patients from 1,400 Commission-Accredited Cancer Programs following survival data until death.35 The United Network for Organ Sharing (UNOS) database was established in 1996 by Congress to track every organ donation event in the USA along with long-term patient and graft survival.36
Resources
The application of EBM practices requires a functional knowledge of how to identify, interpret, and implement the information available into care plans and practice guidelines. Although many institutions have entire departments focusing on EBM utilization, not all physicians have ready access to the information. In the field of surgery, there are many examples of heterogeneous care plans within institutions and group practices despite convincing, high-level evidence. Also, there are many reasons for these often conflicting care plans. One is that personal bias for some providers is stronger than their ability to interpret data. Thus, they continue working in their comfort zone and are skeptical of sound data. Some of these surgeons completed training in the apprentice era, and they have continued to follow what their chief told them. Also, some physicians who understand the principles of EBM simply do not have wide access to the evolving body of EBM. To overcome some of these hurdles, several web-based support sites have been developed for both EBM tutorial and review of available studies. A few examples are listed in Table 78-3.
TABLE 78-3
Websites that Pertain to Evidence-Based Medicine
| Name of Website | Address |
| The Cochrane Collaboration | www.cochrane.org |
| The Cochrane Library | www3.interscience.wiley.com |
| National Guideline Clearinghouse | www.guideline.gov |
| Centre for Evidence-Based Medicine | www.cebm.net |
| Berkeley Systematic Reviews Group | http://epi.berkeley.edu/ |
| Clinical Evidence | www.clinicalevidence.org |
| Evidence-Based Medicine Resource Center | www.ebmny.org |
| Welch Medical Library | http://welch.jhmi.edu/welchone/ |
| Prime Answers | www.primeanswers.org |
| Evidence-Based Practice Centers | www.ahrq.gov |
| PubMed | www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=PubMed |
References
1. Sackett, DL, Rosenberg, WM, Gray, JA, et al. Evidence based medicine: What it is and what it isn’t. BMJ. 1996; 312:71–72.
2. Steffens, BB. Ibn Al-Haytham: First Scientist. Greensboro, NC: Morgan Reynolds Publishing; 2006.
3. Bacon F. Novum Organum, 1620.
4. Cochrane, AL. Effectiveness and Efficiency: Random Reflections on Health Services. London: Nuffield: Provincial Hospitals Trust; 1972.
5. www.cochrane.org. http://www3.interscience.wiley.com/cgi-bin/mrwhome/106568753/HOME
6. Eddy, DM. Practice policies: Where do they come from? JAMA. 1990; 263:1265–1272.
7. Guyatt, G, Cairns, J, Churchill, D, et al. (Evidence-Based Medicine Working Group): Evidence-based medicine: A new approach to teaching the practice of medicine. JAMA. 1992; 268:2420–2425.
8. Harbour, R, Miller, J. A new system for grading recommendations in evidence based guidelines. BMJ. 2001; 323:334–336.
9. Atkins, D, Briss, PA, Eccles, M, et al. GRADE Working Group. Systems for grading the quality of evidence and the strength of recommendations II: Pilot study of a new system. BMC Health Serv Res. 2005; 5:25–37.
10. West, S, King, V, Carey, TS, et al. Systems to rate the strength of scientific evidence. Rockville, MD: Agency for Healthcare Research and Quality (AHRQ publication No. 02–E016); 2002.
11. Jüni, P, Altman, DG, Egger, M. Assessing the quality of randomised controlled trials. In: Egger M, Davey Smith G, Altman DG, eds. Systematic reviews in health care: Meta-analysis in context. London: BMJ Books; 2001:87–121.
12. Zaza, S, Wright-De, A, Briss, PA, et al. Data collection instrument and procedure for systematic reviews in the guide to community preventive services. Am J Prev Med. 2000; 18:44–74.
13. Atkins, D, Best, D, Briss, PA. Grading quality of evidence and strength of recommendations. BMJ. 2004; 328:1490.
14. GRADE Working Group: David Atkins, Dana Best, Peter A Briss, Martin Eccles, Yngve Falck-Ytter, Signe Flottorp, Gordon H Guyatt, Robin T Harbour, Margaret C Haugh, David Henry, Suzanne Hill, Roman Jaeschke, Gillian Leng, Alessandro Liberati, Nicola Magrini, James Mason, Philippa Middleton, Jacek Mrukowicz, Dianne O’Connell, Andrew D Oxman, Bob Phillips, Holger J Schünemann, Tessa Tan-Torres Edejer, Helena Varonen, Gunn E Vist, John W Williams Jr, Stephanie Zaza.
15. Overview of the American Recovery and Reinvestment Act of 2009 (Recovery Act). Agency for Healthcare Research and Quality (AHRQ), Rockville, MD, 2010. http://www.ahrq.gov/fund/cefarraover.htm
16. St. Peter, SD, Adibe, OO, Iqbal, CW, et al. Irrigation versus suction alone during laparoscopic appendectomy for perforated appendicitis: A prospective randomized trial. Ann Surg. 2012; 256:581–585.
17. St. Peter, SD, Tsao, K, Spilde, TL, et al. Thoracoscopic decortication versus tube thoracostomy with fibrinolysis for empyema in children: A prospective, randomized trial. J Pediatr Surg. 2009; 44:106–111.
18. Sonnappa, S, Cohen, G, Owens, CM, et al. Comparison of urokinase and video-assisted thoracoscopic surgery for treatment of childhood empyema. Am J Respir Crit Care Med. 2006; 174:221–227.
19. Fraser, JD, Aguayo, P, Leys, CM, et al. A complete course of intravenous antibiotics versus a combination of intravenous and oral antibiotics for perforated appendicitis in children: A prospective, randomized trial. J Pediatr Surg. 2010; 45:1198–1202.
20. St. Peter, SD, Tsao, K, Spilde, TL, et al. Single daily dosing ceftriaxone and Flagyl versus standard triple antibiotic regimen for perforated appendicitis in children: A prospective, randomized trial. J Pediatr Surg. 2008; 43:981–985.
21. St. Peter, SD, Barnhart, DC, Ostlie, DJ, et al. Minimal versus extensive esophageal mobilization during laparoscopic fundoplication: A prospective randomized trial. J Pediatr Surg. 2011; 46:163–168.
22. Blakely, ML, Williams, R, Dassinger, MS, et al. Early versus interval appendectomy for children with perforated appendicitis. Arch Surg. 2011; 146:660–665.
23. St. Peter, SD, Weesner, KA, Weissand, EE, et al. Epidural versus patient controlled analgesia for pain control following pectus excavatum repair: A prospective, randomized trial. J Pediatr Surg. 2012; 47:148–153.
24. St. Peter, SD, Adibe, OO, Juang, D, et al. Single incision versus standard laparoscopic 3 port appendectomy: A prospective, randomized trial. Ann Surg. 2011; 254:586–590.
25. Adibe OO, St. Peter SD. Ethical ramifications from the loss of equipoise and the necessity of randomized trials. Arch Surg. In Press
26. Ehrlich, PF, Newman, KD, Haase, GM, et al. Lessons learned from a failed multi-institutional randomized controlled study. J Pediatr Surg. 2002; 37:431–436.
27. Outcomes Research. Fact Sheet. AHRQ Publication No. 00-P011. Agency for Healthcare Research and Quality, Rockville, MD, 2000. http://www.ahrq.gov/clinic/outfact.htm
28. Abdullah, F, Ortega, G, Islam, S, et al. Outcomes research in pediatric surgery. Part 1: Overview and resources. J Pediatr Surg. 2011; 46:221–225.
29. Overview of HCUP-SID Database. Healthcare Cost and Utilization Project (HCUP). Agency for Healthcare Research and Quality, Rockville, MD, 2010. www.hcupus.ahrq.gov/sidoverview.jsp
30. Overview of HCUP-KID Database. Healthcare Cost and Utilization Project (HCUP). Agency for Healthcare Research and Quality, Rockville, MD, 2010. www.hcupus.ahrq.gov/kidoverview.jsp
31. Overview of the American College of Surgeons National Surgical Quality Improvement Program. c2006 [cited 2010 Jul]. Available from https://acsnsqip.org/main/about_overview.asp.
32. Overview of the American College of Surgeons National Surgical Quality Improvement Program- Pediatrics. c2009 [cited 2010 Jul 31]. Available from http://www.pediatric.acsnsqip.org/default.aspx.
33. American College of Surgeons Committee on Trauma- Overview of the National Trauma Data Bank. c1996–2010 [updated 2010 April 20; cited 2010 Jul 31]. Available from http://www.facs.org/trauma/ntdb/ntdbapp.html.
34. Overview of the Surveillance, Epidemiology, and End Results Data sets. [Updated 2010 April 14; cited 2010 Jul 31]. Available from http://seer.cancer.gov/data/.
35. American College of Surgeons Commission on Cancer- Overview of the National Cancer Data Base. c2002–2010 [updated 2010 June 2; cited 2010 Jul 31]. Available from http://www.facs.org/cancer/ncdb/index.html.
36. USA Department of Health and Human Services- Health Resources and Services Administration-Organ Procurement and Transplantation Network- Overview of the United Network for Organ Sharing. [Cited 2010 Jul 31]. Available from http://optn.transplant.hrsa.gov/data/about/.
[/level-membership-for-pediatrics-category][not-level-membership-for-pediatrics-category]
Evidence-Based Medicine
‘In God we trust; all others must bring data.’
—W. EDWARDS DEMING, PHYSICIST AND QUALITY IMPROVEMENT PIONEER
Evidence-based medicine (EBM) is defined as the conscientious, explicit, and judicious use of the current best evidence in making decisions about the care of individual patients.1 A simpler concept would be treating patients based on data rather than the surgeon’s thoughts or beliefs. EBM represents the concept that medical practice can be largely dictated by evidence gained from the scientific method. Given that the practice of medicine has historically been based on knowledge handed down from mentor to apprentice, the concepts of EBM embody a new paradigm, replacing the traditional paradigm that was based on authority. In a global sense, it describes a methodology for evaluating the validity of clinical research and applying those results to the care of patients.
History
The initial groundwork forming the framework for EBM can be considered the earliest scientists who pursued explanatory truth instead of accepting beliefs. The process of discovering truth became replicable for aspiring scientists when the scientific method was developed. No one individual can be credited for creating the scientific method because it is the result of the progressive recognition for a natural process of acquiring facts. However, the earliest publication alluding to the steps of current scientific methodology may be found in Book of Optics published in 1021 by Ibn al-Haytham (Alhazen).2 His investigations were based on experimental evidence. Furthermore, his experiments were systematic and repeatable as he demonstrated that rays of light are emitted from objects rather than from the eyes. In Western literature, Roger Bacon wrote about a repeating cycle of observation, hypothesis, and experimentation in the 1200s. Influenced by the contributions of many scientists and philosophers, Francis Bacon delineated a recognizable form of the scientific method in the 1620 publication of Novum Organum Scientificum.3 He suggested that mastery of the world in which man lives is dependent on careful understanding. Moreover, this understanding is based entirely on the facts of this world and not, as the ancients portrayed it, in philosophy. Nearly 400 years later, we find ourselves coming to the same conclusions in the practice of medicine and surgery. We now understand that facts and truths transcend experience, and that facts about optimal care can be gained through experimentation more reliably than from beliefs generated through experience.
The establishment of the scientific method in the pursuit of proven truths was fundamental to the development of EBM as an entity. The current scientific method consists of several steps that are outlined in Box 78-1. However, the concepts of EBM are not simply encompassed by the application of these steps to attain facts, but also address the ability to understand the value of the results generated from experimentation. Under the auspices of EBM, investigators are burdened with the first five steps, from inquiry to experimentation, while all caregivers must develop a deep understanding of experimental methodology, analysis of data, and how conclusions are drawn to be able to place appropriate value on published studies to influence their practice.
The movement urging physicians to utilize proven facts in the development of decision-making algorithms began in 1972 with the publication of the revolutionary book Effectiveness and Efficiency: Random Reflections on Health Services.4 The author, Archie Cochrane, a Scottish epidemiologist working in the UK National Health Service, has likely had the greatest influence on the development of an organized means of guiding care through data and results. The book demonstrates disdain for the scientific establishment, devalues expert opinion, and shows that physicians should systematically question what is the best care for the patient. Most impressively, Cochrane calls for an international registry of randomized controlled trials and for explicit quality criteria for appraising published research. At the time of his passing in 1988, these aspirations had not fully materialized. However, the field of medicine is fortunate that Cochrane’s prophetic ideas have precipitated the maturation of centers of EBM research that make up the global not-for-profit organization called the Cochrane Collaboration. The product of this collaboration is The Cochrane Library, which is a collection of seven databases that contain high-quality, independent evidence to inform health care decision-making.5 The most clinically utilized database is the Cochrane Database of Systematic Reviews containing reviews on the highest level of evidence on which to base clinical treatment decisions. There are now over 550,000 entries.
After Cochrane and other proponents of EBM showed the importance of comparative data, it took over a decade for the amorphous clouds of these concepts to solidify into tangible terms and usable methods. The methodology of specifically qualifying data and judging the relative merits of available studies did not begin to appear in the literature until the early 1990s. In a paper published in 1990 by David Eddy on the role of guidelines in medical decision-making, the term evidence-based first appeared in the literature.6 Much of the framework currently used to determine best available evidence was established by David Sackett and Gordon Guyatt at the McMaster University-based research group called the Evidence-Based Medicine Working Group. In 1992, JAMA published the group’s landmark paper titled, ‘Evidence-Based Medicine: A New Approach to Teaching the Practice of Medicine,’ and the term evidence-based medicine was born.7 A cementing moment in the paradigm shift occurred when the Centre for Evidence-Based Medicine was established in Oxford, England, in 1995 as the first of several centers. Over the past decade, centers or departments focusing on clinical research and EBM have been developed at universities and hospitals around the world, including our own (www.cmhclinicaltrials.com). EBM principles are now represented in the core curriculum that is integral to three of the six general competencies outlined by the Accreditation Council for Graduate Medical Education that oversees the accredited residency training programs in the United States. The concept of EBM is no longer a movement of progressive physicians, but rather a basic guiding principle of medical training and practice.
Levels of Evidence
Level 1—evidence is supported by prospective, randomized trials
Level 2—evidence is supported by cohort studies, outcomes data, or low-quality prospective trials
Level 3—evidence comprises case-control studies
Level 4—evidence is based on case series
Level 5—evidence is expert opinion or beliefs based on rational principles.
The quality of data that is conveyed within each level and study type is clearly a wide spectrum. The complete delineation in the levels of evidence as defined by the Oxford Centre for Evidence-Based Medicine is outlined in Table 78-1.
TABLE 78-1
Levels of Evidence as Defined by the Oxford Centre for Evidence-Based Medicine
| Level | Type of Evidence |
| 1a | Systematic review of randomized trials displaying homogeneity |
| 1a− | Systematic review of randomized trials displaying worrisome heterogeneity |
| 1b | Individual randomized controlled trials (with narrow confidence interval) |
| 1b− | Individual randomized controlled trials (with a wide confidence interval) |
| 1c | All or none randomized controlled trials |
| 2a | Systematic reviews (with homogeneity) of cohort studies |
| 2a− | Systematic reviews of cohort studies displaying worrisome heterogeneity |
| 2b | Individual cohort study or low-quality randomized controlled trials (<80% follow-up) |
| 2b− | Individual cohort study or low-quality randomized controlled trials (<80% follow-up/wide confidence interval) |
| 2c | ‘Outcomes’ research; ecological studies |
| 3a | Systematic review (with homogeneity) of case-control studies |
| 3a− | Systematic review of case-control studies with worrisome heterogeneity |
| 3b | Individual case-control study |
| 4 | Case series (and poor quality cohort and case-control studies) |
| 5 | Expert opinion without explicit critical appraisal, or based on physiology, bench research, or ‘first principles’ |
As can be seen by the levels listed in Table 78-1, the strength of evidence improves significantly by the application of prospective data collection. In clinical medicine, and particularly in the practice of surgery, many aspects of trial design are not feasible such as blinding, placebo treatments, independent follow-up evaluation, and others. However, if one accepts these limitations and conducts a trial with prospective evaluation, the results remain markedly more meaningful than a retrospective case-control comparative series that compares surgeons and/or timeframes against one another.
The review of several studies can gain strength over an individual study, which is valid in many models and fields of medicine. However, one should be cautioned about the real strengths of such a meta-analysis before considering it to have a high level of evidence. The strength of these combined reviews is derived from the strength of the individual trials providing the numbers for the analysis. In the best scenario, such a combined review is composed of multiple prospective trials with similar design that each compares the effect of two treatments on a specific outcome. However, in the field of pediatric surgery, multiple prospective trials with similar designs that address the same disease with the same interventions are nonexistent. Also, surgeons should not overvalue the influence of combined reviews derived from retrospective studies. Such reviews should be interpreted as a mosaic of the individual studies. Any attempt by authors to combine a number of retrospective studies to harness statistical power is fraught with hazard.
Grades of Recommendation
The quality of the evidence as defined in Tables 78-1 and 78-2 applies a score of strength for each individual contribution in the literature. However, on many topics, particularly common clinical scenarios, there is an abundance of published studies such that the appropriate care cannot be guided by a single study. The total body of available information places caregivers in the difficult position of evaluating the published principles from the multiple sources that make up practice guidelines. The caregiver applying these clinical practice guidelines and other recommendations needs to know how much confidence can be placed in the recommendations from a conglomerate of citations. Strength of recommendation scales were born from this need.8–12 Given that the level of evidence indicates the extent to which one can be confident that an estimate of effect is correct, the strength or grade of recommendation indicates the extent to which one can be confident that adherence to the recommendation will do more good than harm.13 As with the levels of evidence, there are multiple published grading scales. The grading format used by the Oxford Centre for Evidence-Based Medicine is outlined in Table 78-2.
TABLE 78-2
Grades of Recommendation as Defined by the Oxford Centre for Evidence-Based Medicine
| Grade | Level of Evidence |
| A | Consistent level 1 studies |
| B | Consistent level 2 or 3 studies or extrapolations from level 1 studies |
| C | Level 4 studies or extrapolations from level 2 or 3 studies |
| D | Level 5 evidence or troublingly inconsistent or inconclusive studies of any level |
[/not-level-membership-for-pediatrics-category]
