227 Evidence-Based Critical Care
The practice of critical care, like all fields of medicine, is changing constantly, and the pace of change is ever increasing. Among the many forces for change, the rapid increase in information is one of the most important. Although the majority of practitioners do not engage in research themselves, they are consumers of research information and must therefore understand how research is conducted to apply this information to their patients. Fellowship programs in critical care medicine emphasize education in this area to varying degrees. The traditional approach has been to require fellows to actively participate in a research project, either clinical or basic science. However, there has also been a growing interest in instructing fellows in the methods of clinical epidemiology.1 The practical application of clinical epidemiology is evidence-based medicine (EBM), which Sackett defines as “the conscientious and judicious use of current best evidence in making decisions about the care of individual patients.”2 The clinical practice of EBM involves integrating this evidence with individual physician expertise and patient preferences so informed, thoughtful medical decisions are made.3 In this chapter we present the methodology of EBM and its application in critical care medicine.
 Asking a Question
Asking a Question
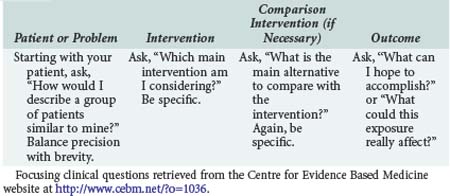
The first step in practicing EBM is asking a well-constructed clinical question. To benefit the patient and aid the clinician, clinical questions must be both directly relevant to patients’ problems and constructed in a way that guides an efficient literature search to relevant and precise answers. The Centre for Evidence Based Medicine (CEBM) in Oxford, England, provides an excellent description of the four essential elements of an EBM question, summarized in Table 227-1.
 Types of Evidence
Types of Evidence
Primary Research
Randomized Clinical Trials
Randomized clinical trials, also referred to as experimental or interventional studies, are the cornerstones of medical evidence. Physicians place considerable faith in the results of randomized control trials.4,5 This faith is placed with good reason, as randomization remains perhaps the best solution to avoid misinterpreting the effect of a therapy in the presence of confounding variables.6 When participants are randomly allocated to groups, factors other than the variable of interest (e.g., a new therapy for sepsis) that are likely to affect the outcome of interest are usually distributed equally to both groups. For example, with randomization, the number of patients with underlying comorbidity that may adversely affect outcome should be similar in each study arm, presuming sample size is appropriate. A special advantage of randomization is that this equal distribution will occur for all variables (excluding the intervention) whether these variables are identified by the researcher or not, thus maximizing the ability to determine the effect of the intervention.
However, RCTs are expensive, difficult, and sometimes unethical to conduct, with the consequence that less than 20% of clinical practice is based on the results of RCTs.7 Moreover, many important questions such as determining the optimal timing of a new therapy or determining the effects of health care practices cannot practically be studied by RCTs.
Observational Studies
Observational outcomes studies are very powerful tools for addressing many questions that RCTs cannot address, including measuring the effect of harmful substances (e.g., smoking and other carcinogens), organizational structures (e.g., payer status, open versus closed ICUs), or geography (e.g., rural versus urban access to health care). Because of their cost and the regulatory demands on drug and device manufacturers, RCTs are frequently designed as efficacy studies in highly defined patient populations with experienced providers and therefore provide little evidence about effectiveness in the “real” world.8 Alternatively, observational studies can generate hypotheses about the effectiveness of treatments that can be tested using other research methods.8 Investigators have also explored the effects of different therapies that are already accepted but used variably in clinical practice.9
However, observational studies have several significant limitations. First, the data source must be considered. Observational outcomes studies are often performed on large data sets wherein the data were collected for purposes other than research. This can lead to error owing to either a lack of pertinent information or bias in the information recorded.10 Second, one must consider how the authors attempt to control for confounding. The measured effect size of a variable on outcome (e.g., the effect of the pulmonary artery catheter on mortality rate) can be confounded by the distribution of other known and unknown variables. More specifically, case-control studies are subject to recall and selection bias, and the selection of an appropriate control group can be difficult. Cross-sectional studies can only establish association (at most), not causality, and are also subject to recall bias. Cohort studies have a number of limitations, including difficulty in finding appropriate controls and difficulty determining whether the exposure being studied is linked to a hidden confounder, and the requirement of large sample size or long follow-up to sufficiently answer a research question can be timely and expensive.
Single-Study Results—Critically Appraised Topics
Determining which studies provide information useful in the care of patients is largely a question of deciding whether a study is valid and, if so, can its results be applied to the patients in question. One format for appraising individual studies is the critically appraised topic (CAT) format that has been popularized as part of EBM. The purpose of the CAT is to evaluate a given study or set of studies using a standardized approach. Studies that address diagnosis, prognosis, etiology, therapy, and cost-effectiveness all have a separate CAT format.3 An example is shown in Box 227-1 for studies that address therapy. The CAT format for studies on therapy asks several questions intended to address the issues of validity and clinical utility. Studies that fail to achieve these measures are not generally useful, although studies do not necessarily have to fulfill every criterion, depending on the nature of the topic. For example, a study that examined the effect of walking once a day for the prevention of stroke would not be expected to include a detailed examination of side effects or a cost-effectiveness analysis. However, a study comparing streptokinase to placebo for treatment of stroke would likely be required to include a detailed examination of side effects and a cost-effectiveness analysis because of the excessive risks and costs associated with such therapy. Similarly, blinding may not always be possible, and the effects of the investigators being unblinded can be minimized by separating them from the clinicians making the treatment decisions or by establishing standard treatment protocols that are applied equally to both the study and control groups. Alternatively, a study would be “fatally flawed” if it failed in terms of randomization or was not analyzed as “intention to treat.” There are a number of other useful tools for assessing study design and for quantifying effect size and cost-effectiveness. In general, these are the tools of epidemiology and biostatistics, and their discussion is beyond the scope of this chapter. A basic primer and glossary of terms is included in Table 227-2.

Systematic Reviews of Multiple Studies
The disadvantage of systematic reviews is that they are only as good as the studies they include and can only be interpreted if all the criteria just mentioned have been met. Unfortunately, there is considerable variability in the quality and comprehensiveness of available systematic reviews. Much of this dilemma stems from a lack of commonly accepted methodology for conducting and writing systematic reviews. For example, there are no standard exclusion criteria for studies in systematic reviews. Each author establishes the criteria, which the reader must assess to determine the quality and utility of the review to answer his clinical question. In addition, there is publication bias. Popular search techniques to identify studies are inherently limited by the fact that unpublished studies are unaccounted for in any review. Issues such as these have led authors to propose the development and maintenance of study registries where all RCTs are registered irrespective of their publication status.11 This would enable review of smaller studies and those studies published in journals not listed in cumulative Index Medicus, MEDLINE, and other popular databases in systematic reviews.
Narrative Reviews of Multiple Studies
The advantage of narrative reviews is that they provide a detailed qualitative discussion, usually by an expert with years of experience. However, they do have several limitations. The most important of these is that evidence used to support the author’s positions is not collected, evaluated, and compared in an organized and reproducible manner. That information is complete or that it is judged in an unbiased manner cannot be assured. Journal articles are often peer reviewed, which provides some limited oversight for completeness and lack of bias, but this is far from perfect. Furthermore, review articles and textbook chapters are not generally subject to vigorous review and therefore may be the least reliable sources of information, particularly current information. For example, by 1988, fifteen studies had been reported on the use of prophylactic lidocaine in acute myocardial infarction. While no single study was definitive, pooled data from the nearly 9000 patients showed that the practice was useless at best. Nonetheless, by 1990 there were still more recommendations for its use than against it appearing in textbooks and review articles.12
 Appraising Evidence
Appraising Evidence
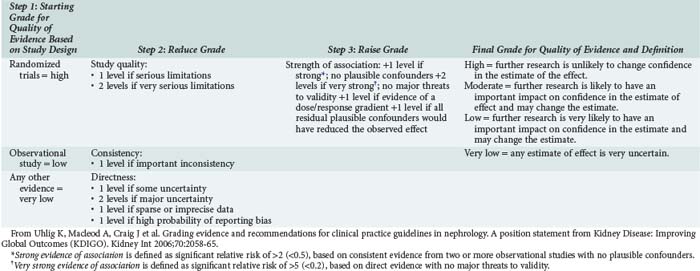
For a piece of evidence to be useful, it has to be valid, have clinically important findings, and be applicable to the particular patient. Guides for assessment of validity, like that shown in Box 227-1, exist for different types of studies (e.g., therapy, diagnosis, prognosis) and are presented in detail in Evidence-Based Medicine.13 Worksheets to determine whether a study is valid are also available from a number of sources including the Centre for Evidence Based Medicine (www.cebm.net). The importance of findings again depends on the type of study. For studies on therapy, the clinician must decide if there was a true treatment effect and, if so, how large an effect. For studies on diagnosis, the characteristics of a test must be presented, and the clinician must decide if the test characteristics (sensitivity, specificity, positive and negative predictive values) would make the same test useful for current patients. Again, a number of guides exist to help physicians make these decisions. In the last few years, the GRADE (Grades of Recommendation Assessment, Development and Evaluation) Workgroup has proposed a mythology for evidence appraisal that has been widely adopted.14 Table 227-3 summarizes the GRADE System. High-grade evidence should, in theory at least, be adopted into clinical practice and forms the basis of guidelines, whereas a more nuanced approach is needed for lesser-quality evidence.
 Applying Evidence
Applying Evidence
Bedside Decision Making
The goal of EBM is to facilitate bedside decision making by placing evidence in the context of clinical judgment and the preferences of the patient.15 There is often sufficient medical evidence to influence a number of daily decisions. Therefore, the clinician should always ask, “Is my patient receiving the best level of care as indicated by the evidence in the literature? Are there any study protocols or results that could be applied to this patient that currently are not?” Clinicians should also recognize knowledge deficits and be alert for opportunities to formulate EBM questions during daily rounds or routine patient care. Once the evidence is found and deemed useful, it must be judiciously applied. Clinicians must use their knowledge and experience to understand how to apply the results of studies to individual patients. Some cases, owing to patient- or environment-specific circumstances, may be sufficiently unique to render even good evidence inappropriate. Individual patient or family values and expectations could also direct therapy in one direction when medical evidence and physician judgment would have led it in another.
Guidelines and Protocols
Perhaps a natural extension of EBM is the desire to standardize care when evidence can be found for treatments or diagnostic procedures that are cost-effective. When such therapeutic or diagnostic strategies exist, they should be widely applied. A convenient way to ensure this is to develop a protocol or guideline. Protocols and guidelines are especially useful for common illnesses and procedures and have the advantage of allowing an institution to implement EBM even in the presence of physician lack of expertise in EBM. However, developing and maintaining protocols and guidelines is extremely labor intensive because the EBM criteria for guideline validity are explicit. Sackett states, “We should think of [a guideline] as having two distinct components: first the evidence summary, and second, the detailed instructions for applying that evidence to our patient.”13 The evidence summary consists of a recent review of the literature both for and against the guideline.3 The applicability of the guideline in each clinical situation with particular patient and institutional characteristics is assessed in the same manner as other evidence.
 Problems with Evidence-Based Medicine in Critical Care
Problems with Evidence-Based Medicine in Critical Care
Generating Evidence
It is impossible to practice EBM without a body of evidence in the literature. Until recently, there was little strong evidence supporting particular care paradigms in the critically ill. There are now a large number of studies guiding a wide set of critical care problems,16–21 whereas other elements of care remain largely empirical. Why has our field had such difficulty conducting clinical trials? There are a number of reasons. First, critical illness occurs in a heterogeneous group of patients in whom treatment effects may be small. Narrow selection criteria may introduce bias, and smaller sample sizes may not show an effect. Second, investigators must ensure the novel therapy is tested against “current best methods of care.” Since a study will be interpreted in the light of likely treatment patterns at the completion of a trial rather than the initiation, recent strong evidence should be promoted in both arms of a trial. But the large number of recent critical care trials combined with the financial and practical difficulties of implementing all of the changes has made “current best methods of care” an evolving process that remains a constantly moving target. Third, the choice of appropriate outcomes continues to be debated in critical care. The historic choice of 28-day (or 30-day) mortality rate, which has been used as the primary outcome in most critical care trials,22 has been criticized as arbitrary and incomplete. There is growing recognition that clinical research has to define and focus on the outcomes most meaningful to patients and society, including quality of life, functional status, freedom from pain and other symptoms, and satisfaction with medical care.8
Reporting Results
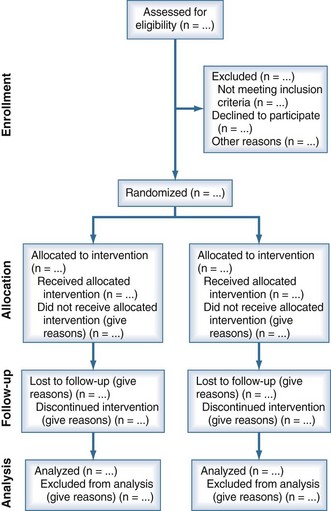
Another threat to the validity of EBM is the accessibility to evidence as a function of study results reporting. Randomized trials can yield biased results if they lack methodological rigor, and it may be difficult to determine their flaws if they are not reported accurately. Unfortunately, authors of many trial reports neglect to provide lucid and complete descriptions of critical information needed to judge the methodological rigor and hence the validity of the results. In response to this problem, a series of Consolidated Standards of Reporting Trials (CONSORT) statements were published beginning in 1996.23 Most recently, these statements have been updated with CONSORT 2010.24 Figure 227-1 shows a flow diagram for reporting information on research subjects in a parallel randomized trial of two groups. CONSORT 2010 also provides a 25-point checklist for information to include when reporting a randomized trial. The hope is that by improving and standardizing trial reporting, evidence appraisal will be more objective and overall evidence quality will improve.
Practicing When Evidence Is Lacking
Although the application of EBM has produced very useful information to guide therapy25 and further research,26 it has also generated considerable controversy.27–29 The disagreement is not over recommendation of practices based on sound evidence, but instead whether these practices should be avoided when evidence is lacking. Thus clinicians are weary of being told they and their patients cannot pursue diagnostic and therapeutic choices because there is no evidence these practices work. In this regard, it is important to note one of the basic principles of EBM: “not finding an effect is not the same as finding no effect.” Stated differently, the lack of evidence that something works is not evidence that it does not work. This issue is particularly relevant to critical illness where, by definition, patients are seriously ill and often do not respond to therapy. Should treatment that is possibly effective be withheld from patients with otherwise lethal conditions on grounds that it is unproved?
For new therapies, there are already evidence-based standards in place for evaluation and approval.30 However, numerous therapies are in use in the ICU today without proven efficacy, and many others, for which there may be proof in one patient population, are being prescribed in another. Unfortunately, there may be significant barriers to obtaining evidence for these practices. For example, funding agencies and corporations may be unwilling to study therapies that are no longer patented. Furthermore, placebo-controlled studies are often impossible to conduct because clinicians find it unethical to withhold “standard” therapies. Efforts to use “lack of evidence” to justify withholding these therapies should be tempered by these and the following considerations:
Barriers to Applying Evidence
When we see patients, we are responsible for applying EBM in the management of their clinical problems. But even when the evidence is strong and the patient is in agreement with the plan, powerful impediments often bar our way.31 As has been experienced by other specialties, critical care medicine has many logistical barriers to implementing EBM at the level of the clinician or the institution and regionally/nationally.
Although the obstacles are significant, we are not without resources to overcome them. Paralleling the evolution of EBM has been research into how evidence can be implemented into practice—so-called implementation research.32 Understanding how individuals and institutions absorb evidence and implement change has, in select cases, translated into fundamental improvements in health care. We have also learned much about barriers to research transfer through our failed attempts to modify behavior. Success in modifying a discrete aspect of medical practice has invariably been achieved through multidisciplinary strategies that meld concepts and techniques from epidemiology, education, marketing, psychology, sociology, and economics.
 Conclusion
ConclusionKey Points
Cook DJ, Sibbald WJ, Vincent JL, Cerra FB. Evidence based critical care medicine: what is it and what can it do for us? Evidence Based Medicine in Critical Care Group. Crit Care Med. 1996;24:334-337.
Evidence-Based Medicine Working Group. Evidence-based medicine: a new approach to teaching the practice of medicine. JAMA. 1992;268:2420-2425.
Sackett DL, Straus SE, Richardson WS, et al. Evidence-based medicine: how to practice and teach EBM. London: Harcourt; 2000.
A comprehensive introduction to EBM and its practice.
Atkins D, Best D, Briss PA, Eccles M, Falck-Ytter Y, Flottorp S, et alGRADE Working Group. Grading quality of evidence and strength of recommendations. BMJ. 2004;328:1490.
The GRADE recommendations are outlined and explained.
Schulz KF, Altman DG, Moher D. CONSORT 2010 statement: updated guidelines for reporting parallel group randomized trials. for the CONSORT Group. Ann Intern Med. 2010;152:726-732.
An update to the original CONSORT guidelines for conduct and reporting of clinical trials.
1 Kellum JA, Rieker JP, Power M, Powner DJ. Teaching critical appraisal during critical care fellowship training: A foundation for evidence-based critical care medicine. Crit Care Med. 2000;28:3067-3070.
2 Sackett DL, Rosenberg WM, Gray JA, et al. Evidence based medicine: What it is and what it isn’t. BMJ. 1996;312:71-72.
3 Sackett DL, Haynes RB, Tugwell P. Clinical Epidemiology: A Basic Science for Clinical Medicine. Boston: Little, Brown; 1985.
4 Ware JH, Antman EM. Equivalence trials. N Engl J Med. 1997;337:1159-1161.
5 Lamas GA, Pfeffer MA, Hamm P, et al. Do the results of randomized clinical trials of cardiovascular drugs influence medical practice? The SAVE Investigators. N Engl J Med. 1992;327:241-247.
6 Lavori PW, Louis TA, Bailar JC3rd, Polansky M. Designs for experiments—parallel comparisons of treatment. N Engl J Med. 1983;309:1291-1299.
7 Committee for Evaluating Medical Technologies in Clinical Use, Institute of Medicine, Division of Health Sciences Policy, Division of Health Promotion, Disease Prevention: Assessing Medical Technologies. Washington, DC: National Academy Press, 1985.
8 Rubenfeld GD, Angus DC, Pinsky MR, et al. Outcomes research in critical care: Results of the American Thoracic Society Critical Care Assembly Workshop on Outcomes Research. Am J Respir Crit Care Med. 1999;160:358-367.
9 McClellan M, McNeil BJ, Newhouse JP. Does more intensive treatment of acute myocardial infarction in the elderly reduce mortality? Analysis using instrumental variables. JAMA. 1994;272:859-866.
10 Iezzoni LI, Foley SM, Daley J, et al. Comorbidities, complications, and coding bias. Does the number of diagnosis codes matter in predicting in-hospital mortality? JAMA. 1992;267:2197-2203.
11 Pignon JP, Arriagada R. Meta-analyses of randomized clinical trials: How to improve their quality? Lung Cancer. 1994;10(Suppl 1):S135-S141.
12 Mulrow CD. Rationale for systematic reviews. In: Chalmers I, Altman DG, editors. Systematic reviews. London: BMJ Publishing Group; 1995:1-8.
13 Sackett DL, Straus SE, Richardson WS, et al. Evidence based medicine: how to practice and teach EBM. London: Harcourt Publishers Limited; 2000.
14 Atkins D, Best D, Briss PA, et al. Grading quality of evidence and strength of recommendations. BMJ. 2004 Jun 19;328(7454):1490.
15 Cook DJ, Hebert PC, Heyland DK, et al. How to use an article on therapy or prevention: Pneumonia prevention using subglottic secretion drainage. Crit Care Med. 1997;25:1502-1513.
16 Rivers E, Nguyen B, Havstad S, et al. Early goal-directed therapy in the treatment of severe sepsis and septic shock. N Engl J Med. 2001;345:1368-1377.
17 Hebert PC, Wells G, Blajchman MA, et al. A multicenter, randomized, controlled clinical trial of transfusion requirements in critical care. Transfusion Requirements in Critical Care Investigators, Canadian Critical Care Trials Group. N Engl J Med. 1999;340:409-417.
18 The ARDS Network authors for the ARDS Network. Ventilation with lower tidal volumes as compared with traditional tidal volumes for acute lung injury and the acute respiratory distress syndrome. N Engl J Med. 2000;342:1301-1308.
19 Bernard GR, Vincent JL, Laterre PF, et al. Efficacy and safety of recombinant human activated protein C for severe sepsis. N Engl J Med. 2001;344:699-709.
20 Drakulovic MB, Torres A, Bauer TT, et al. Supine body position as a risk factor for nosocomial pneumonia in mechanically ventilated patients: A randomised trial. Lancet. 1999;354:1851-1858.
21 Kress JP, Pohlman AS, O’Connor MF, Hall JB. Daily interruption of sedative infusions in critically ill patients undergoing mechanical ventilation. N Engl J Med. 2000;342:1471-1477.
22 Wood KA, Huang D, Angus DC. Improving clinical trial design in acute lung injury. Crit Care Med. 2003;31:S305-S311.
23 Begg C, Cho M, Eastwood S, et al. Improving the quality of reporting of randomized controlled trials. The CONSORT statement. JAMA. 1996;276:637-639.
24 Schulz KF, Altman DG, Moher D, for the CONSORT Group*. CONSORT 2010 Statement: updated guidelines for reporting parallel group randomized trials. Ann Intern Med. 2010;152:726-732.
25 Cook DJ, Guyatt GH, Laupacis A, Sackett DL. Rules of evidence and clinical recommendations on the use of antithrombotic agents. Chest. 1992;102:305S-311S.
26 Sibbald WJ, Vincent JL. Roundtable Conference on Clinical Trials for the Treatment of Sepsis. Brussels, March 12-14, 1994. Chest. 1995;107:522-527.
27 Cassiere HA, Groth M, Niederman MS. Evidence-based medicine: The wolf in sheep’s clothing. In: Yearbook of intensive care and emergency medicine. Heidelberg: Springer-Verlag; 1998:744-749.
28 Charlton BG. Restoring the balance: Evidence-based medicine put in its place. J Eval Clin Pract. 1997;3:87-98.
29 Sullivan FM, MacNaughton RJ. Evidence in consultations: Interpreted and individualised. Lancet. 1996;348:941-943.
30 Eddy DM. Investigational treatments: how strict should we be? JAMA. 1997;278:179-185.
31 Haynes RB, Sackett DL, Gray JM, et al. Transferring evidence from research into practice: I. The role of clinical care research evidence in clinical decisions. ACP J Club. 1996;125:A14-A16.
32 Grol R, Jones R. Twenty years of implementation research. Fam Pract. 2000;17(Suppl 1):S32-S35.
